

Процесс поиска и выявления закономерностей и зависимостей в практически полезных данных проводится методами интеллектуального анализа данных (Data Mining) путем исследования множества рассматриваемых объектов. В основной своей массе оно заключается в представлении исследуемых данных в табличном виде, где каждая строка соответствует одному из вариантов состояния рассматриваемого объекта, а столбцы содержат значения параметров, которые его характеризуют [1]. Выявление закономерностей и взаимосвязей предполагает наличие зависимой переменной. Она представляет из себя параметра, значение которого рассматривается как зависящее от других известных и заданных независимых переменных (параметров). Исходя из этого, задачей интеллектуального анализа данных (Data Mining) является определение взаимозависимости между исходными данными.
Рассмотрим основные задачи интеллектуального анализа данных (Data Mining) [2]:
1) Задача классификации. Она заключается в том, что для каждого варианта определяется категория или класс, которому он принадлежит.
2) Задача регрессии. Оно во многом схожа с задачей классификации, но в ходе ее решения производится поиск шаблонов для определения числового значения.
3) Задача кластеризации (сегментации). Она заключается в делении множества объектов на группы (кластеры) схожих по параметрам.
4) Задача определения взаимосвязей (поиска ассоциативных правил). Она также называемая задачей поиска ассоциативных правил, заключается в определении часто встречающихся наборов объектов среди множества подобных наборов.
5) Анализ последовательностей или сиквенциальный анализ. Целью данного анализа является обнаружение закономерностей в последовательностях событий.
6) Анализ отклонений. Он позволяет отыскать среди множества событий те, которые существенно отличаются от нормы.
Современные принципы организации и управления экономикой требуют от специалиста знания новых методов анализа и прогнозирования реальных экономических процессов, основанных на интеллектуальном анализе данных. Одним из инструментов интеллектуального анализа данных экономических показателей является аналитическая платформа Deductor Studio — программа, позволяющая проводить всесторонний анализ финансово-хозяйственной деятельности предприятия и прогнозировать его экономические показатели.
Архитектура аналитической платформы Deductor Studio позволяет реализовать все этапы построения аналитической системы: от создания хранилища данных предприятия до настройки корпоративной аналитической отчетности [3]. Deductor Studio позволяет аналитику автоматизировать рутинные операции по обработке данных и сосредоточиться на интеллектуальной работе: формализация логики принятия решений, построение моделей, прогнозирование.
В результате работы данного компонента аналитической платформы Deductor Studio строится линейная модель данных. Применяется следующий алгоритм построения модели.
Пусть имеется набор входных значений Xi, где i = 1 ... n, т.е X = {x1,x2, ... , xn}. Тогда можно указать такой набор выходных значений Yj (j = 1 … m), который будет соответствовать линейной комбинации входных значений с коэффициентами аi (i = 1 … n):
[1, x1, x2, ... , xn] [a0, a1, a2, ..., an] = [y1, y2 ,..., ym] (1.1)
Если для простоты предположить, что выходное значение одно, то можно записать:
a0 + x1a1 + x2a2 + …+ xnan = y (1.2)
Таким образом, задача сводится к подбору коэффициентов ai. Их оценка производится путем метода наименьших квадратов (МНК).
Однако, следует отметить, что использования метода линейной регрессии предназначена для поиска только линейных зависимостей в данных. В случае, когда зависимость нелинейная, то построенная модель, скорей всего, будет недостаточно точной. Это можно увидеть на диаграмме рассеяния, так как разброс прогнозных значений величины будет сильно велик относительно действительных значений. В данном случае необходимо использовать более эффективные алгоритмы, например, нейронные сети.
В первую очередь, для того, чтобы начать использовать нейросеть, ее необходимо обучить. Задача обучения здесь равносильна задаче аппроксимации функции, то есть восстановление функции по отдельно взятым ее точкам – таблично заданной функции [4]. В силу этого, для обучения нейросети необходимо подготовить обучающую выборку, то есть таблицу с входными значениями и соответствующими им выходными значениями. Такая таблица поможет нейросети самой обнаружить взаимосвязи и зависимости выходных полей от входных. Далее, подавая на вход нейросети некоторые значения, можно использовать эти взаимосвязи и зависимости. На выходе будут восстановлены зависимые от них значения, причем на вход можно подавать значения, на которых нейросеть не обучалась [5].
В работе будет исследоваться зависимость чистой прибыли от основных средств, запасов, денежных средств и нераспределенной прибыли (непокрытого убытка), а также построится прогноз на следующий отчетный период.
Под самой чистой прибылью понимается часть балансовой прибыли предприятия, остающаяся в его распоряжении после уплаты налогов, сборов, отчислений и других обязательных платежей в бюджет. Чистая прибыль используется для увеличения оборотных средств предприятия, формирования фондов и резервов, и реинвестиций в производство.
Данный показатель будет рассматриваться как эндогенный фактор, поскольку получение прибыли обычно является главной целью всех видов предпринимательства.
Чистая прибыль Y в нашей модели будет зависит от следующих показателей:
1. Основные средства – это материальные активы, которые предприятие содержит с целью использования их в процессе производства или поставки товаров, предоставления услуг, сдачи в аренду другим лицам или для осуществления административных и социально-культурных функций.
Зависимость между основными средствами и чистой прибылью компании показывает эффективность использования имеющихся ресурсов, которые в свою очередь напрямую влияют на чистую прибыль организации, поэтому данный фактор включаем в модель как экзогенный фактор Х1.
2. Запасы – это активы, используемые в качестве сырья, материалов и т. п. при производстве продукции, предназначенной для продажи (выполнения работ, оказания услуг), приобретаемые непосредственно для перепродажи, а также используемые для управленческих нужд организации.
Управление запасами для получения прибыли является одной из наиболее сложных и главных задач руководства организации. Запасы зачастую являются самыми крупными оборотным активом предприятия. Поэтому сумма, отнесенная на запасы, напрямую влияет на сумму чистой прибыли, значит данный фактор включаем в модель как экзогенный фактор Х2.
3. Денежные средства - это наличные деньги в кассе организации, средства на банковских счетах и средства, воплощенные в денежных документах.
Денежные средства участвуют в процессе производства и управления, а значит увеличение или уменьшение чистой прибыли пропорционально их росту или уменьшению, поэтому данный фактор включаем в модель как экзогенный фактор Х3.
4. Нераспределенная прибыли (непокрытый убыток) - это прибыль (убыток) компании, фирмы, акционерного общества, остающаяся после уплаты налогов и выплаты дивидендов, используемая для реинвестирования, на нужды развития или же убытки, который понесла фирма за время ведения всех видов деятельности за предыдущие отчетные периоды
Нераспределенная прибыли и непокрытый убыток влияют на чистую прибыль, потому что, например, прибыль, не инвестированная в активы фирмы, может сказаться на прибыли следующих периодов. Точно так же из-за непокрытого убытка средства придется направлять на его погашение, что скажется на значении чистой прибыли следующих периодов. Поэтому данный фактор включаем в модель как экзогенный фактор X4.
Для проведения интеллектуального анализа выбранных экономических показателей необходимо импортировать текстовый файл с их значениями за разные периоды непосредственно в аналитическую платформу Deductor Studio (Рисунок 1).
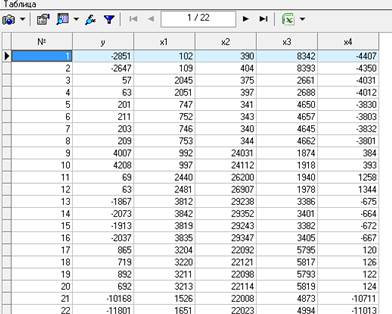
Рисунок 1 - Исходная таблица данных в программе Deductor Studio
Далее на основании импортированных данных необходимо провести анализ методом прогнозирования с помощью линейной регрессии. Для того, чтобы его провести, нужно в меню найти раздел «Мастер обработки» и выбрать в качестве обработки данных «Линейную регрессию» (Рисунок 2).
Рисунок 2 - Мастер обработки сценариев
После выбора нужного метода обработки данных необходимо задать назначение для исходных столбцов (Рисунок 3).
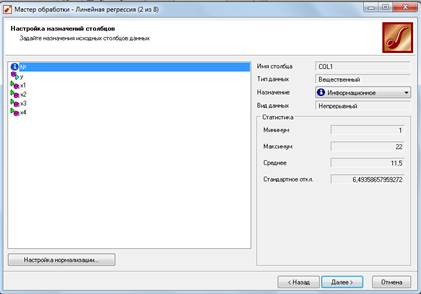
Рисунок 3 - Настройка назначения столбцов
В данном случае для номеров наблюдения было выбрано назначение «Информационное», так как они являются вспомогательными, то есть их не следует использовать при обработке. Для всех значений Х укажем назначение «Входное», так как предполагается, что они влияют на Y. Соответственно, для значения Y присвоим назначение «Выходное»
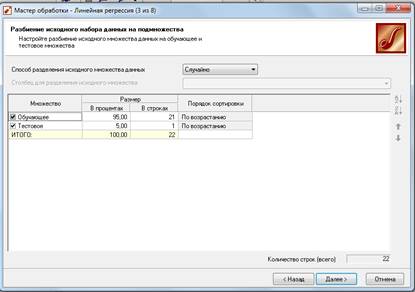
На следующем шаге происходит настройка обучающего и тестового множеств и способ разложения исходного множества данных (Рисунок 4).
 .
.
Рисунок 4 - Разбиение исходного множества на подмножества
Далее установщик позволяет осуществить ограничение диапазона входных значений. Данный шаг оставим без изменений.
После выполнения процесса выберем в качестве способа отображения «Коэффициенты регрессии», «Отчет по регрессии» и «Диаграмму рассеяния».
По рассчитанным коэффициентам регрессии (Рисунок 5) можно сделать следующие выводы:
1. Чистая прибыль предприятия без учета включенных в модель факторов будет составлять 6570,1 тыс. руб.
2. При увеличении основных средств на 1 тыс. руб. при неизменном уровне других факторов чистая прибыль уменьшится на 0,61 тыс. руб.
3. При увеличении запасов на 1 тыс. руб. при неизменном уровне других факторов чистая прибыль уменьшиться на 0,13 тыс. руб.
4. При увеличении денежных средств на 1 тыс. руб. при неизменном уровне других факторов чистая прибыль уменьшится на 0,39 тыс. руб.
5. При увеличении суммы нераспределенной прибыли на 1 тыс. руб. при неизменном уровне других факторов чистая прибыль увеличится на 1,1 тыс. руб.
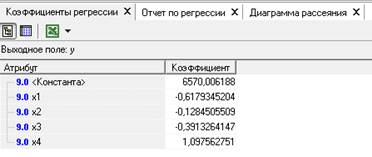
Рисунок 5 - Коэффициенты регрессии
Благодаря анализу регрессии (Рисунок 6) можно сделать выводы относительно выбранных нами параметров, а именно: значение коэффициента детерминации R-квадрат, который равен 0,918, говорит нам о том, что у чистой прибыли сильная связь с выбранными факторами. Следовательно, в 91,8 % случаев изменение чистой прибыли компании связано с изменением включенных в модель факторов.
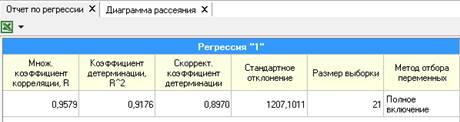
Рисунок 6 - Отчет по регрессии
Кроме этого, из диаграммы рассеянья (Рисунок 7) видно, что разброс между эталонными значениями выходного поля и значениями, рассчитанными моделью, достаточно невелик. Из этого можно сделать вывод, что временной ряд хорошо укладывается в линейную модель и, следовательно, на основании этой модели можно строить прогноз на будущие периоды времени.
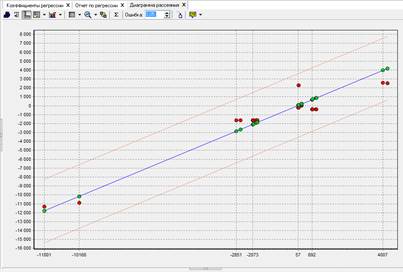
Рисунок 7 - Диаграмма рассеивания
Следующим и последним шагом является прогнозирование. Для построения прогноза чистой прибыли на следующий период необходимо на основании построенной регрессии в разделе «Мастере обработки» выбрать в качестве обработки данных «Прогнозирование». В результате чего в исходную таблицу добавится новая строка с прогнозным значением чистой прибыли на следующий период (Рисунок 8).
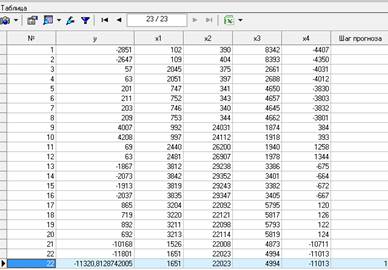
Рисунок 8 – Прогнозное значение
Так как значения нераспределенной прибыли в таблице за последнее время отрицательное, то мы имеем дело с непокрытым убытком. По уравнению регрессии увеличение этого фактора увеличивает прибыль, но по последним данным вместо прибыли организация несет убыток, а значит увеличение значения непокрытого убытка увеличит убыток в следующем году. Отсюда следует, что надо уменьшить значение непокрытого убытка, чтобы организация начала получать прибыль или сократила численное значение убытка. Это она может сделать за счет резервного фонда, добавочного капитала или привлечения средств из вне, то есть инвестиций или целевых взносов учредителей. Кроме того, увеличение расходов на материальные активы тоже уменьшает прибыль. Исходя из этого, для увеличения чистой прибыли или сокращения убытка необходимо сократить значения этих факторов.
На основании этого прогноза можно сделать вывод, что убыток в следующий квартал сократиться с 11801 тыс. руб. до 11321 тыс. руб. Однако в связи с тем, что для получения прогноза на большое число шагов используются не реальные, а вычисленные с использованием модели данные, ошибка такого прогноза может быть довольно значительной. Поэтому при построении прогноза на длительный период величина погрешности возрастает с каждым новым шагом, что существенно снижает ценность прогноза. Поэтому для более точных прогнозов и более серьезного анализа данная модель нуждается в дополнительных данных.