

Введение. Машинное обучение является областью исследований, где изучаются методы построения алгоритмов для искусственного интеллекта. Подходы, основанные на машинном обучении, показали достойные результаты в прогнозировании поведения пользователей в сети [1, 3, 7, 8]. Одним из направлений в создании моделей для прогнозирования поведения пользователя, является модель распространения информации в Интернете [9].
Действительно, изучая то, как данные распространяются в течение долгого времени, является полезным методом в понимании поведения пользователей в Интернете [2]. Другим направлением является использование различных функций данных для более детальной картины поведения пользователей. Первое направление дает лишь очень грубое представление о поведении пользователей в сети. Напротив, функциональный подход, основанный на модели на более низком уровне детализации, может обеспечить высокую точность модели [4, 10, 11].
Логистическая регрессия
Логистическая регрессия – это статистическая модель, используемая для прогнозирования вероятности возникновения некоторого события путём подгонки данных к логистической кривой.
Основными преимуществами логистической регрессии являются: способность интерпретировать построенную модель, высокая производительность для больших наборов данных, а также многомерное пространство признаков.
В работе [2] авторы анализировали влияние особенностей вопросов на время откликов на сайте StackOverflow. Авторы использовали данные, собранные с сайта в течение четырех лет (с 2008 по 2012 года). Данные представлены на рисунке 1.
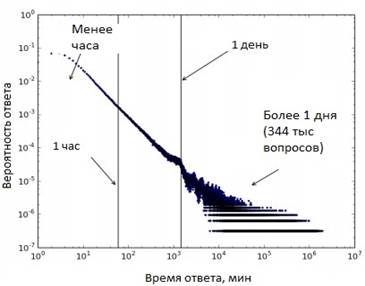
Рисунок 1. Зависимость вероятности ответа от времени
Авторы решали две задачи: спрогнозировать будет ли дан ответ на поставленный вопрос в течение 16 минут; спрогнозировать будет ли дан ответ на вопрос меньше чем за 1 час или будет ждать более 1 суток.
После обработки и анализа данных были определены факторы оказывающие наибольшее влияние на выходную функцию скорости и точности ответа: популярные тэги (столбец 2), процент активных подписчиков (столбец 3), конкретные (специфичные) тэги (столбец 4), все вышеперечисленные функции (столбец 5). Сравнение производилось с вопросом без тэга (столбец 1). Эксперимент проводился с помощью машинного обучения, основанного на таких методах как: логистическая регрессия, линейный и нелинейный метод опорных векторов и дерево решений. Результаты первого эксперимента представлены на рисунках 2 и 3.
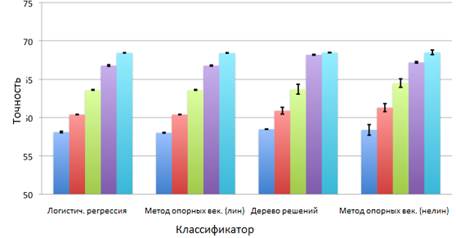
Рисунок 2. Точность ответа при решении первой задачи
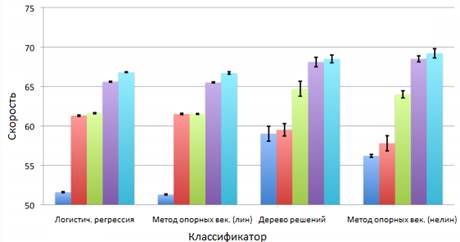
Рисунок 3. Скорость ответа при решении первой задачи
Результаты второго эксперимента – на рисунках 4 и 5.
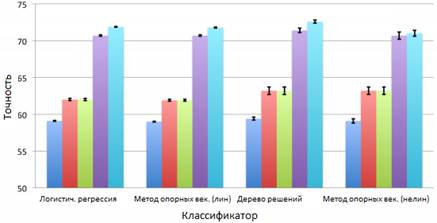
Рисунок 4. Точность ответа при решении второй задачи
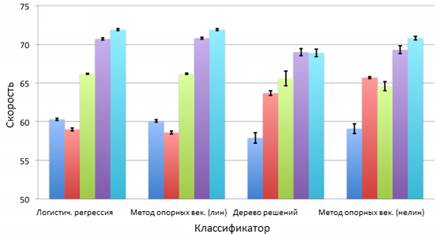
Рисунок 5. Скорость ответа при решении первой задачи
В результате решения обеих задач можно сделать одинаковые выводы: с ростом популярности тегов время отклика уменьшается, вопросы, содержащие слишком конкретные теги, остаются без ответа более длительное время, при увеличении количества подписчиков, время ответа уменьшается.
Метод опорных векторов
Метод опорных векторов – это набор алгоритмов, использующихся для задач классификации и регрессионного анализа. Учитывая, что в N-мерном пространстве каждый объект принадлежит одному из двух классов, данный метод генерирует (N-1) - мерную гиперплоскость с целью разделения этих точек на 2 группы.
В статье [5] авторы изучали проблему понимания важности сообщений в Twitter. Подход к данной проблеме состоял из двух этапов. Во-первых, была собрана статистика об обмене сообщениями и ретвитами между пользователями за продолжительный промежуток времени (с 2006 по 2009 года). Была построена функция распределения (рисунок 6, рисунок 7) в зависимости от времени ожидания ответа и позиции сообщения.
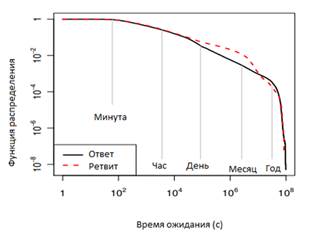
Рисунок 6. Функция распределения в зависимости от времени ожидания
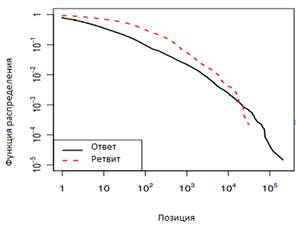
Рисунок 7. Функция распределения в зависимости от позиции сообщения
Затем определяли факторы, которые влияют на реакцию пользователя или вероятность ретвита. Наибольшее влияние на скорость ответа или ретрвита оказывают новизна сообщения, общались ли пользователи до этого или нет, скорость ответа отправителя, а также такие текстовые характеристики как: размер сообщения, наличие хэштегов, ретвитов, URL. Авторы показали, что некоторые из этих факторов могут быть использованы для улучшения представления порядка твитов в пользовательском интерфейсе.
Для подтверждения исходной гипотезы была проведена серия экспериментов, в котором сравнивались способы сортировки с помощью моделей, обученных с помощью байесовского метода и метода опорных векторов с исходным способом сортировки. На рисунках 8 и 9 представлено сравнение количества ответов от позиций для различных способов сортировки для активных и пассивных пользователей
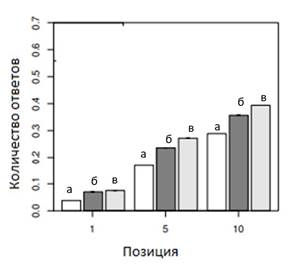
Рисунок 8. Количество ответов в зависимости от позиции для активных пользователей
а) базовая сортировка; б) сортировка с помощью Баейсовского метода; в) сортировка с помощью метода опорных векторов.
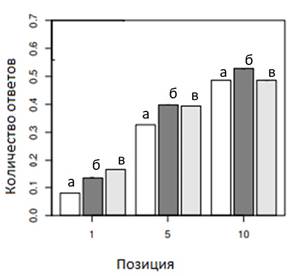
Рисунок 9. Количество ответов в зависимости от позиции для пассивных пользователей
а) базовая сортировка; б) сортировка с помощью Баейсовского метода; в) сортировка с помощью метода опорных векторов.
Таким образом, из представленной диаграммы можно сделать следующие выводы: используя машинное обучение для изменения порядка сообщений можно достичь большего количества ответов и ретвитов; сортировка с помощью метода опорных векторов показывает лучшие результаты для активных пользователей.
Метод ближайших соседей
Идея алгоритма метода ближайших соседей состоит в том, чтобы выбрать k – соседние векторы для входного вектора r как наиболее сходные с входным вектором.
В работе [6] авторы представили новый алгоритм совместной фильтрации на основе памяти для прогнозирования пользовательских отзывов о фильмах с использованием набора данных NetFlix.
Авторы получили список жанров из IMDB для примерно 5 миллионов фильмов, всего 23. Был выполнен простой поиск жанровых меток для всех фильмов NetFlix. Из-за различий в названиях фильмов и датах выпуска между базами данных авторы смогли добиться точного соответствия только для 6658 фильмов NetFlix. Далее был получен список из 33941 пользователей, которые оценили эти фильмы. Из них 3941 пользователь был отведен для целей тестирования, а остальные 30000 пользователей были использованы для определения оптимального значения параметра K в методе ближайших соседей с использованием 5-кратной перекрестной проверки. Каждый пользователь представлен в скрытом жанровом пространстве вектором признаков, накапливая вклад различных жанров фильмов, оцененных им. Для пользователей в наборе тестов один фильм на пользователя используется для прогнозирования метки, а остальные фильмы используются для генерации «частичного» вектора признаков. Тот же подход используется для проверки набора во время обучения. На рисунках 10 и 11 показан вектор признаков, созданный для двух пользователей с использованием их предпочтений фильма. Более высокий вес для таких жанров, как «Комедия», «Роман» и «Триллер» для пользователя 1, показывает симпатию к фильмам с этими конкретными темами, в то время как пользователь 2 предпочитает фильмы «Драма», «Криминал» и «Война».
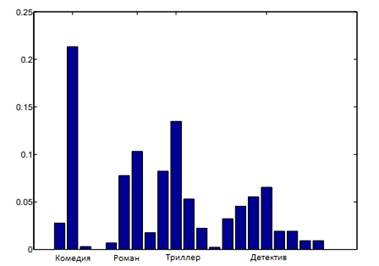
Рисунок 10. Результаты первого пользователя
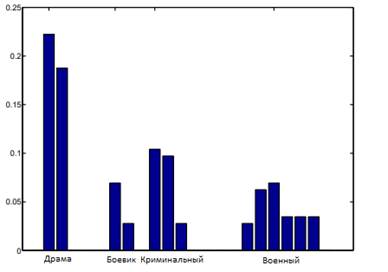
Рисунок 11. Результаты второго пользователя
Чтобы преодолеть проблему векторов функций голосования различной длины и уменьшить вычислительную сложность, работая с подмножеством «подходящих» пользователей, было введено пространство признаков, называемое пространством скрытого жанра. Для эффективного поиска в этом пространстве был использован метод ближайших соседей.
Для окончательной оценки рассмотрели два простых алгоритма для сравнения: первый быть средним числом всех голосов за фильмы (что отражает среднюю неспецифическую для пользователя популярность фильма) и наивным алгоритмом, который всегда рассматривает мнение трех рецензентов. На рисунке 12 показано сравнение ошибки данного алгоритма с двумя вышеперечисленными.
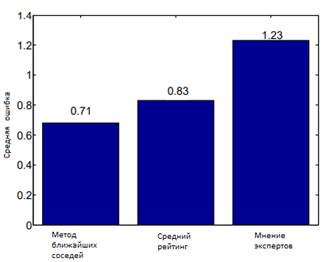
Рисунок 12. Сравнение алгоритмов, используя среднюю ошибку
Результаты данной работы являются многообещающими и превосходят два базовых метода, с которыми происходит сравнение. Недостатками данного алгоритма является, во-первых, жанр фильма может не содержать достаточной информации для решения данной задачи, а также модель полностью игнорирует пользовательские симпатии актерам и режиссерам.
Вывод. При выборе алгоритма, следует учитывать специфику анализируемых данных. Логистическая регрессия подходит для решения прогнозирующих задач благодаря масштабируемости и прозрачности интерпретации результатов.
Метод опорных векторов может показывать более высокую точность в прогнозировании, но он намного дороже в вычислительном плане и труден в интерпретации результатов прогнозирования.
Метод ближайших соседей прост в реализации, но неэффективно расходует вычислительные мощности вследствие необходимости хранения всей обучающей выборки и необходимости линейного сравнения классифицируемого объекта со всеми объектами выборки.