

В наше время рекомендательные системы активно используются в жизнедеятельности человека – мы сталкиваемся с ними повсеместно. С их помощью нам предлагают товары и услуги, которые могут нас заинтересовать.
Коллаборативная фильтрация – это метод, позволяющий предсказать неизвестные предпочтения пользователя на основе известных оценок и/или поведения похожих пользователей. Суть коллаборативной фильтрации заключается в том, что пользователи, одинаково оценившие, какие-либо элементы системы склоны одинаково оценивать и другие элементы системы [1].
Алгоритм включает в себя 3 шага:
1. Для каждого пользователя вычислить насколько его интересы совпадают с интересами пользователя текущего пользователя;
2. Выбрать множество пользователей, наиболее близких к текущему;
3. Предсказать оценку i-го объекта на основе оценок объекта соседей.
Для определения соседства пользователей существует множество различных алгоритмов, например, косинусное, манхэттенское и евклидово расстояния.
Косинусное расстояние определяется как:
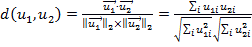 ,
,
где 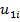 и
и 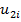 – оценки пользователей.
– оценки пользователей.
Манхэттенское расстояние имеет следующий вид:
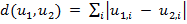 .
.
Метрика в Евклидовом пространстве вычисляется при помощи следующей формулы:
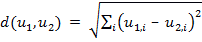 .
.
Для выбора пользователей, наиболее похожих на текущего пользователя, задается константа k. Затем все пользователи сортируются по убыванию меры близости и из этого списка отбираются первые k, наиболее близких к текущему.
Предсказание оценки для i-го объекта на основе оценок объекта соседей осуществляется по следующей формуле:
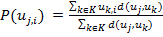 ,
,
где 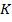 – множество наиболее похожих на
– множество наиболее похожих на 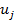 пользователей.
пользователей.
Вторым крупным видом коллаборативной фильтрации является фильтрация, основанная на анализе модели данных. Для данного подхода характерно сначала построение описательной модели предпочтений по совокупности оценок, а затем формирование рекомендации на основании полученной модели. Примером этого вида является кластерная модель.
Одним из самых известных алгоритмов в кластерном анализе является метод k-means или k-средних. Он основан на разделении объектов или пользователей на группы – кластеры, которые создаются по некоторым общим признакам, а количество которых задается заранее. Суть алгоритма состоит в случайном выборе k центров кластера и уменьшении суммарного квадратичного отклонения пользователей или объектов от центра кластера. Формально это вычисляется с помощью следующей формулы:
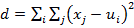 .
.
Цель метода заключается в том, чтобы как можно более точно предсказать оценку, которую поставит текущий пользователь системы ранее неоцененным им объектам (рис.1).
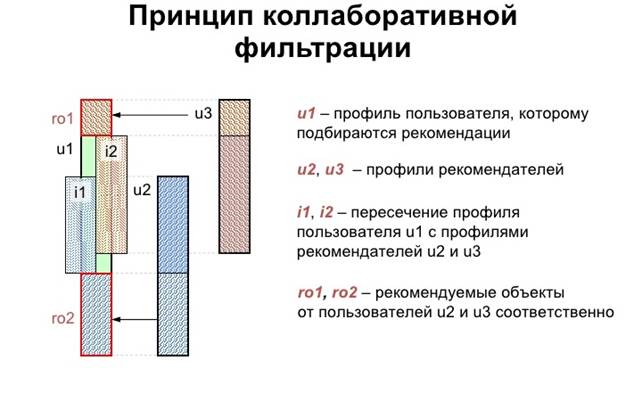
Рисунок 1.
На сегодняшний день коренные изменения в экономической сфере российского общества требуют научного подхода к переосмыслению устоявшихся социальных норм. Важнейшей областью в пространстве социальных отношений является взаимодействие внутри трудового коллектива. От социально-психологической атмосферы в коллективе, специфики организационной культуры во многом зависит не только эффективность совместной деятельности, выражающейся в экономических показателях, но также отношение сотрудников к своей работе, эмоциональный настрой, внешняя мотивация и, в конечном итоге, удовлетворенность работой. В связи с этим, актуальной становится задача разработки новых подходов к формированию рабочих коллективов в малых проектных группах.
По результатам множества опросов менеджеров проектов в России и за рубежом, до 80% успеха при реализации проектов обусловлены слаженной работой проектной команды, которая, в свою очередь, обеспечивается верным распределением ролей среди участников[2]. При распределении ролей необходимо соблюдать два принципа: принцип компетентности и принцип предпочтения[3]. Принцип компетентности – навыков сотрудника должно быть достаточно для исполнения своей роли. Члены команды будут отдавать большее предпочтение тем целевым ролям, которые больше соответствуют их умениям и индивидуальным потребностям, т.е. принижать умения человека тоже не стоит. Принцип предпочтения - как можно большее число членов команды должны получить те роли, которые они предпочитают. Существую такие ситуации, в которых сотрудник не согласен с данной ему ролью, в связи с этим снижается продуктивность этого сотрудника и нарушается взаимодействие между членами команды.
Как было сказано выше, коллаборативная фильтрация — подход к предсказанию предпочтения с использованием исключительно информации о связях пользователей и объектов рекомендации. В нашем случае объектом будет являться роль, которой интересовался пользователь. Сформулируем задачу более строго. Пусть U — множество пользователей (users), I — множество объектов (items), информация об известных предпочтениях представлена в виде набора троек: D = {(u, i, rui)}(u,i)∈R,
где rui ∈ R — вещественная степень предпочтения объекта i ∈ I пользователем u ∈ U; R ⊆ U × I — множество пар (пользователь, объект), про которые известна степень предпочтения. Для дальнейшего удобства, введем также обозначения: R(u) = {i : (u, i) ∈ R} — множество объектов, смежных с пользователем u, аналогично: R(i) = {u : (u, i) ∈ R}. По известной информации D требуется уметь строить предсказание предпочтения rˆui ≈ rui для новых пар (u, i) 6∈ R. Будем называть матрицей оценок матрицу R ∈ (R ∪ ∅) |U|×|I| , строки которой соответствуют пользователям, столбцы — объектам (ролям), а элементы принимают значение rui, если (u, i) ∈ R, иначе — пропуск ∅. На задачу коллаборативной фильтрации можно смотреть как на задачу объединения пользователей с разными предпочтениями к ролям в одну малую группу it разработчиков. Помимо предсказания значения предпочтения, на практике могут быть интересны следующие задачи:
- построение списка рекомендаций из объектов, на которые не известна степень предпочтения (новые для пользователя).
- определение степень похожести объектов и построение списков наиболее похожих.
- обоснование списка рекомендаций: некоторое человеко-понятное пояснение, почему пользователю u был порекомендован объект i.
В малых проектных группах невозможно распределить роли по всем участникам проекта - участников проекта меньше, чем ролей. Но в тоже время важно, чтобы были учтены все первостепенные роли – такие, как руководитель проекта, программист, консультант и т.д. В этом случае роли участников проекта совмещаются, но не стоит забывать, что не все роли можно совмещать друг с другом. Не следует допускать совмещения ролей, которые имеют конфликтные или противоречивые интересы. Разработка – роль которая нуждается в большом количестве времени, так что сотрудников, у которых основной ролью является разработка не стоит нагружать второстепенными ролями, это увеличит время на реализацию проекта.
В нашем случае, необходимо распределить роли между участниками проекта, у каждого из которых может быть более чем одна роль. Для этого нужно сравнить текущую команду с другими подобными командами. К примеру, если в большинстве подобных команд разработчик является одновременно и специалистом по интерфейсу, то, соответственно, в этой команде нужно назначить разработчика специалистом по интерфейсу.
В наше время в высших учебных заведениях активно используются электронные курсы, как замена привычным для нас учебникам и задачникам. У электронных курсов есть огромное преимущество перед бумажными носителями в том, что обновление учебных-методических материалов происходит быстрее, но так же как и учебники они рассчитаны на стандартного пользователя и не учитывают индивидуальности каждого студента. Здесь на помощь и приходит адаптивное обучение, благодаря которому учебный курс «подстраивается» под учащегося. Без сомнений, такой вид обучения можно отнести к перспективному направлению в развитии образования [4]. Для демонстрации эффективности данного метода в качестве примера можно рассмотреть его применение для реализации профессионального обучения, например, по направлению «Программная инженерия».
В процессе обучения студентам предстоит выполнить командный курсовой проект. Для его выполнения учащиеся должны разбиться на группы, в которых каждый студент выполняет отведенную ему роль.
Например, студент интересуется тестированием программных продуктов, найдя подходящий материал, студент сам того не сознавая внесет эту информацию в систему [5]. В дальнейшем от результата работы коллаборативной фильтрации система будет подбирать командам или отдельным разработчикам людей на недостающие роли (рис 2).
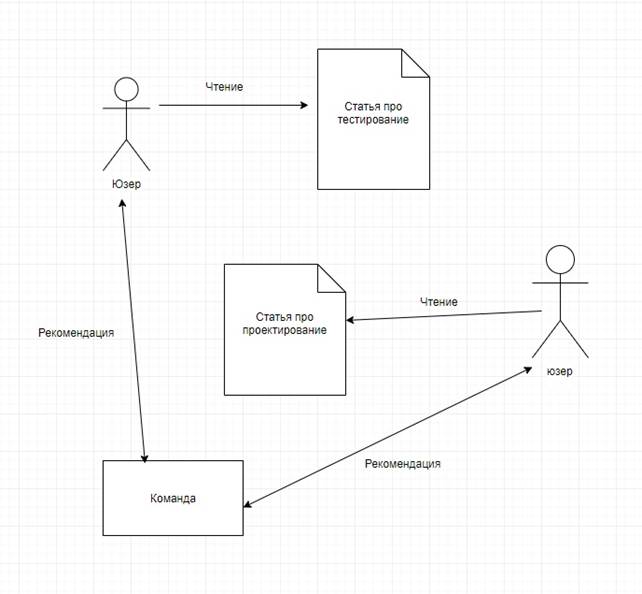
Рисунок 2.
Такая адаптивная система обучения поможет студентам без проблем подобрать команду для выполнения программных проектов. Благодаря такой системе студент будет более углубленно изучать то, что ему нравится.