

Речь каждого человека является неповторимой и имеет целый ряд индивидуальных особенностей. Голос человека столь же уникален, как строение сетчатки глаза или отпечатки пальцев. По голосу человека можно судить о его характере. Также известно, что общее впечатление о человеке наполовину зависит от мимики, на треть - от голоса и только лишь на малую часть - от того, что этот человек говорит.
Индивидуальные особенности голоса говорящего можно использовать не только в задачах идентификации, но и для определения настроения человека, борьбы с телефонными мошенниками и т.д. Круг прикладных задач этим не ограничивается. Так, например, существует зависимость между частотами среднего тона и гендерной принадлежностью - мужчины говорят на частоте 85-200Hz, а женщины — 160-340Hz. Таким образом, можно придумать множество прикладных сценариев, где выделение индивидуальных особенностей говорящего будет необходимо.
Обращаясь к проблеме распознавания речи, прежде всего, необходимо определить, что именно нужно сравнивать. Непосредственное сравнение звуковых сигналов во временной области является процессом долгим и неэффективным. Спектрограммы – более быстрый способ, но не намного эффективнее. Поиски максимально рационального представления приводят к кепстральным коэффициентам, которые часто используются в качестве характеристики речевых сигналов.
Как только слово выделяется из потока входных данных, начинается этап процесса выделение необходимых характеристик. В этом случае могут применяться различные методики, например методика нахождения мел-кепстральных коэффициентов или коэффициентов линейного предсказания. Основная задача на данном этапе - выделение неких параметров сигнала, причем число этих параметров должно быть минимально, чтобы ускорить сравнение с наборами параметров из библиотеки, и в то же время данные параметры должны быть такими, чтобы по ним можно было достаточно точно определить конкретное слово.
Таким образом, можно сделать вывод, что в задачах, связанных с обработкой речи, сигнал не подается напрямую в систему, а представляет собой набор компактных характеристик для наилучшего процесса их манипуляции. Более конкретно, если обратиться к рисунку 1, можно заметить, что для эффективного представления сигнала этап выделения ключевых характеристик речи присутствует как на фазе обучения, так и на фазе выполнения.
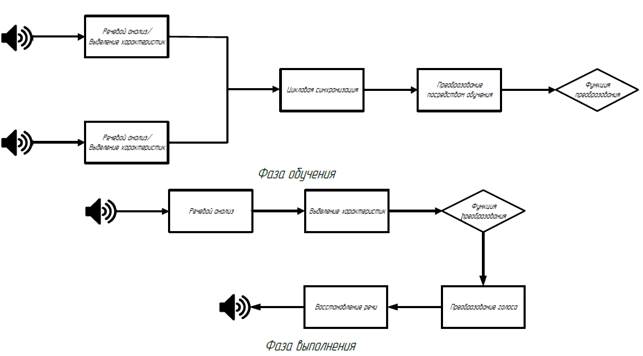
Рисунок 1 – Типовая система преобразования голоса
Обработка спектральных характеристик речи является следствием управления просодией. Однако существует множество представлений спектральных характеристик. Для процесса статистического параметрического моделирования, характеристики должны отвечать следующим требованиям [6]:
- качественно передавать индивидуальные особенности речи диктора как личности;
- в достаточной степени соответствовать спектральной огибающей и обладать способностью в нее преобразовываться;
- обладать качественными свойствами интерполяции и возможностью гибкой модификации.
Спектральные характеристики являются многомерными, поэтому занимают значительную часть памяти при работе с большими объемами данных. Поэтому необходимо прибегнуть к наиболее эффективному одномерному представлению спектра, который может быть использован в дальнейшем на практике [7]. Поиски наиболее рационального представления приводят к кепстральным коэффициентам, которые часто используются в качестве характеристики речевых сигналов.
КЕПСТРАЛЬНЫЕ КОЭФФИЦИЕНТЫ
В процессе эволюции живые существа, обладающие сенсорными системами, развивались по принципу: «различать, для того чтобы выжить». Слуховой аппарат человека как сенсорный анализатор имеет способность обеспечивать различение звуков по их частотному составу. Однако реакция на звуковой стимул должна быть быстрой, а значит, обработка сигналов в ухе и нервной системе должна выполняться за небольшое время. Требования высокой частотной и временной различительной способности анализатора противоречивы, но результатом эволюции было оптимальное сочетание этих показателей.
Органы слуха человека обладают свойством частотного маскирования, где под маскированием понимают ситуацию, при которой нормально слышимый звук накрывается другим громким звуком с близкой частотой. Данная характеристика зависит от частоты сигнала и варьируется от 100 Гц для низких слышимых частот до более 4000 Гц для высоких частот. Следовательно, область слышимых частот можно разделить на несколько критических полос (принято деление на 24 критические полосы), которые обозначают падение чувствительности уха для более высоких частот.
Можно считать критические полосы еще одной характеристикой звука, подобной его частоте. Однако, в отличие от частоты, которая абсолютна и не зависит от органов слуха, критические полосы определяются в соответствии со слуховым восприятием. В итоге они образуют некоторые меры восприятия частот, для которых введены единицы измерения - барк и мел.
Использование кепстрального анализа широко распространено в задачах, связанных с обработкой речи. Большинство современных автоматических систем синтеза и распознавания речи сосредотачивают усилия на извлечении частотной характеристики речевого тракта человека, отбрасывая при этом характеристики сигнала возбуждения. Это объяснено тем, что коэффициенты первой модели обеспечивают лучшую разделимость звуков. Для отделения сигнала возбуждения от сигнала речевого тракта прибегают к кепстральному анализу.
Модель кепстральных коэффициентов, как для минимумов, так и для максимумов оптимально соответствует спектральной огибающей - важной характеристике синтеза речи. Частный случай кепстральных коэффициентов - Мел-кепстральные коэффициенты, представляющие собой спектральную огибающую с коэффициентами, расположенными друг от друга на расстоянии по шкале Мела, которые сосредоточены на частотах, имеющих большое значение для человеческой речи и слуха [1]. Их использование в задаче описания характеристик фонемы обусловлено прежде всего удобством практического применения.
Мел-кепстральные коэффициенты обладают повышенной помехоустойчивостью и позволяют принимать достоверные решения на относительно коротких интервалах анализа речи. Основной идеей метода Мел-кепстральных коэффициентов является максимальное приближение информации поступающей на слуховой анализатор мозга человека. Признаки, построенные на основе Мел-кепстральных коэффициентов, учитывают психоакустические принципы восприятия речи, поскольку используют мел-шкалу, связанную с критическими полосами слуха.
Необходимо понимать значение понятий мела и кепстра. Мел - это единица высоты звука, которая основана на восприятии этого звука органами слуха человека или, другими словами, своеобразное представление энергии спектра сигнала, которое обычно является вектором из тринадцати вещественных чисел. Кепстр (cepstrum) - в свою очередь, это результат дискретного косинусного преобразования от логарифма амплитудного спектра сигнала.
Для того чтобы найти энергию сигнала, вектор спектра сигнала перемножается с функцией окна, в результате чего получается вектор коэффициентов. Если их возвести в квадрат, представить в виде логарифма и получить из них кепстральные коэффициенты, то получаются искомые Мел-коэффициенты. Кепстральные коэффициенты можно получить как с помощью Фурье-преобразования, так и с помощью дискретного косинусоидального преобразования [6]. Дискретное косинусоидальное преобразование применяется для получения кепстральных коэффициентов, оно сжимает полученные результаты, повышает вклад первых коэффициентов и понижает вклад последних.
Плюсы использования кепстральных коэффициентов заключаются в следующем:
· Используется спектр сигнала (то есть разложение по базису ортогональных косинусоидальных или синусоидальных функций), что позволяет учитывать волновую «природу» сигнала при дальнейшем анализе;
· Спектр проецируется на специальную Мел-шкалу, позволяя выделить наиболее значимые для восприятия человеком частоты;
· Количество вычисляемых коэффициентов может быть ограничено любым значением (например, 12), что позволяет «сжать» фрейм и, как следствие, количество обрабатываемой информации;
В работе [5] был предложен унифицированный подход к спектральному анализу речи, позволяющий вычислять различные наборы параметров. В эти параметры, помимо прочих, входят линейное предсказание и Мел-кепстральный анализ. За счет изменения параметров α и γ, есть возможность выбирать между доступными параметрами.
Кепстр 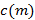 действительной последовательности
действительной последовательности 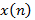 определяется как обратное преобразование Фурье логарифмического спектра, в то время как Мел-обобщенные кепстральные коэффициенты
определяется как обратное преобразование Фурье логарифмического спектра, в то время как Мел-обобщенные кепстральные коэффициенты 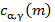 определяются как обратное преобразование Фурье обобщенного логарифмического спектра, рассчитанное по деформированной частотной шкале
определяются как обратное преобразование Фурье обобщенного логарифмического спектра, рассчитанное по деформированной частотной шкале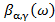 :
:
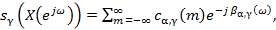 (1)
(1)
где 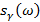 - обобщенная логарифмическая функция и
- обобщенная логарифмическая функция и 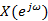 – преобразование Фурье для
– преобразование Фурье для 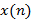 . Обобщенная логарифмическая функция определяется следующим образом:
. Обобщенная логарифмическая функция определяется следующим образом:
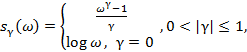 (2)
(2)
а деформированная шкала частот 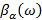 рассчитывается как фазовая характеристика пропускающей системы [2]:
рассчитывается как фазовая характеристика пропускающей системы [2]:
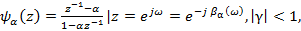 (3)
(3)
где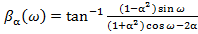 . (4)
. (4)
В работе [4] допускается, что спектр речи 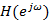 может быть смоделирован
может быть смоделирован 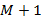 Мел-обобщенными кепстральными коэффициентами следующим образом:
Мел-обобщенными кепстральными коэффициентами следующим образом:
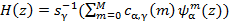 (5)
(5)
Выбрав 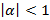 и
и 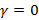 , можно получить Мел-кепстральную функцию (MCEP):
, можно получить Мел-кепстральную функцию (MCEP):
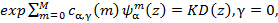 (6)
(6)
где
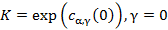 , (7)
, (7)
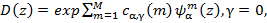 (8)
(8)
а 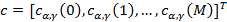 – вектор Мел-кепстральных коэффициентов со специальным коэффициентом
– вектор Мел-кепстральных коэффициентов со специальным коэффициентом 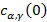 , обычно называемым энергетической компонентой, так как он соответствует средней логарифмической мощности кадра [4]. Вычислительная сложность алгоритма кепстрального преобразования при использовании быстрого преобразования Фурье приближенно равна
, обычно называемым энергетической компонентой, так как он соответствует средней логарифмической мощности кадра [4]. Вычислительная сложность алгоритма кепстрального преобразования при использовании быстрого преобразования Фурье приближенно равна 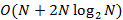 .
.
Мел-обобщенные кепстральные коэффициенты широко используются в проектах, связанных с преобразования голоса, позволяют достигать лучшей производительности по сравнению с другими вариантами и обеспечивают качественное квантование, интерполяцию и представление формантной структуры. Их использование также позволяет избегать создания артефактов в процессе синтеза речи[3].