

Теория графов – область дискретной математики, особенностью которой является геометрический подход к изучению объектов. Основной объект теории графов – граф и его обобщения.
Через V обозначим множество, соединенных некоторым образом точек. Назовем V – множеством вершин, а элементы V вершинами. Граф G = G(V) есть некоторое семейство пар точек Е(а; в), a ∈V, в∈V, с указаниями, какие точки считаются соединенными.
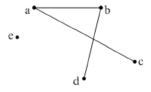
Рис. 1
Например, граф показанный на рис. 1, задан вершинами V = (a, b, c, d, e), а множество E имеет вид E ((a,b), (a,c), (a,d), (b,d)).
В соответствии с геометрическим представлением графа, каждая конкретная пара соединенных точек (а, в) называется ребром. Далее будем говорить, что вершины а и в инцидентны ребру (а, в). Вершина е выше построенного графа, не инцидентна никакому ребру. (инцидент от лат. inсidепs – столкновение). Такие вершины будем называть изолированными. В наших рассмотрениях несущественно прямые линии соединяют вершины, или же вершины соединены непрерывными дугами.
Пример.
План города можно рассматривать как граф, в котором ребра представляют улицы, а вершины перекрестки.
Локальные степени:
Пусть G = G(V) – граф и a∈V его вершина. Число р(а) ребер графа инцидентных 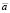 называется локальной степенью графа G в вершине а.
называется локальной степенью графа G в вершине а.
Теорема. Сумма всех локальных степеней графа является четным числом.
Доказательство. Каждому ребру соответствуют две вершины, следователь-но, каждое ребро учитывается дважды.
Следствие. В графе число вершин а с нечетной степенью р(а) всегда чётно.
Граф называется однородным, если р(а) = р(в) для всех его вершин. В этом случае, если р(а) = п, то граф называется однородным степени n.
Примером однородного графа степени 2 является многоугольник без
самопересечений.
Связность. Расстояния в связном графе:
Цепью называется последовательность ребер, встречающихся не более одного раза, в которой два соседние ребра имеют общую вершину.
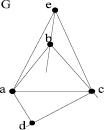
Рис. 2
Например, в графе G последовательность ребер (a, b), (b, c), (c, d),(d, b), (b, e) будет цепью.
Замкнутая цепь называется циклом.
Граф называется связным, если любую его вершину можно соединить с любой другой, цепью, состоящей из ребер графа.
Теорема: Граф с п вершинами и числом ребер большим, чем 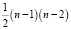 , связан.
, связан.
Пусть а и в две вершины графа. Рассмотрим кратчайшую цепь (цепь, содержащую наименьшее число ребер среди всех соединяющих а и в цепей). Число ребер этой цепи обозначим через d (а: в). Это число назовем расстоянием между вершинами а и в.
Функция d (а: в) удовлетворят всем обычным аксиомам расстояния:
1) d (а: в) = О, если а = в,
2) d (а: в) ≥ 0,
3) d (а: в) = d (в: а),
4) справедливо неравенство треугольника d (а: в) + d (в:c) ≥ d (а: c).
Граф называется полным, если любые две его вершины образуют ребро. Отметим, что граф будет полным, если d (а: в) = 1 для всех несовпадающих вершин графа.
Диаметром графа (Д) называется максимальное расстояние между двумя точками графа, точнее Д = max(d(a, в)|, a ∈V, в∈V).
Деревья:
Рис. 3
Связный граф называется деревом, если он не имеет циклов, т.е. замкнутых цепей.
Теорема: В дереве любые две вершины связаны единственной цепью.
Доказательство. В противном случае был бы цикл.
Задача. Необходимо соединить п различных городов линиями электропередач так, чтобы не строить лишних линий. Из теоремы 1 сразу следует, что схема этих линий должна образовать дерево. Возникает вопрос о числе различных деревьев с п – вершинами.
Теорема: Число различных деревьев. которые можно построить на п верши нах, равно (п-2).
Ориентированный граф:
Определение. Ориентированным графом называется совокупность множества точек и совокупность ориентированных дуг, соединяющих эти точки.
Применение теории графов:
При анализе надежности сетей связи, электрических схем, коммуникационных сетей возникает задача о нахождении количеств непересекающихся цепей, соединяющих различные вершины графа, и она успешно решается с помощью теории графов.
На практике результат одного решения заставляет нас принимать следующее и т.д. Эту последовательность нельзя выразить таблицей доходов, поэтому необходимо использовать другой процесс принятия решений, а именно – «дерево» решений.
«Дерево» принятия решений – это своеобразное средство поддержки принятия решений при прогнозировании, оно широко применяется в статистике и анализе данных.
Прежде чем говорить о конкретных алгоритмах «дерева» решений, необходимо обратить внимание на основополагающие понятия, связанные с данным методом в целом [1].
Итак, «дерево» решений, подобно его «прототипу» из живой природы, состоит из «ветвей» и «листьев». Ветви, а иначе ребра графа, хранят в себе значения атрибутов, от которых зависит целевая функция. Листья – хранят запись о значении целевой функции. Существуют также родительский узел (предок) и дочерний узел(потомок), по которым происходит разветвление (рис. 4).
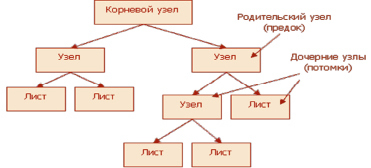
Рис. 4. Общий вид «дерева» решений
Цель построения дерева принятия решений – создать модель, по которой можно классифицировать случаи и решать, какие значения может принимать целевая функция, имея на входе несколько переменных.
Например, когда необходимо принять решение о выдаче кредита (целевая функция может принимать значения «да» и «нет») на основе информации о клиенте (несколько переменных: возраст, семейное положение, место работы и т.д.) К примеру, переменная «возраст» с атрибутом «менее 21года = да» сразу приведет от корневого узла дерева к его листу, при этом целевая функция «выдача кредита» примет значение «нет». Если возраст составляет более 21 года, то ветвь приведет нас к очередному узлу, который, к примеру, «спросит» нас о стабильности дохода клиента. Таким образом, классификация каждого нового случая происходит при движении вниз до листа, который и укажет нам значение целевой функции в каждом конкретном случае [2].
Рассмотрим на данном примере и общий алгоритм построения «дерева» решений. Вначале необходимо выбрать атрибут Q (в нашем случае, допустим: уровень дохода больше 50 000 руб./месяц) и поместить его в корневой узел.
Далее, из тестовых примеров (или набора данных) для каждого значения атрибута i (в нашем случае их два – «да» и «нет») выбираем только те, для которых Q=i. В конечном итоге мы рекурсивно строим «дерево» принятия решений.
На данный момент существует большое количество частных алгоритмов, которые помогают в реализации «дерева» решений CART, C4.5, NewId, ITrule, ID3, CN2 и т.д. Но наибольшее распространение и популярность получили только два:
- CART (ClassificationandRegressionTree) – это алгоритм построения бинарного «дерева» решений – дихотомической классификационной модели. Каждый узел дерева при разбиении имеет только два дочерних узла. Данный алгоритм решает задачи регрессии и классификации.
- C4.5 – это алгоритм построения «дерева» решений, количество дочерних узлов здесь не ограничено. Решает только задачи классификации, так как не умеет работать с непрерывным целевым полем.
Большинство из перечисленных выше алгоритмов являются «жадными алгоритмами». То есть, если один раз был выбран атрибут, по которому было произведено разбиение на подмножества, то такой алгоритм не может вернуться назад и выбрать иной атрибут, который дал бы лучшее разбиение [3].
Таким образом, «дерево» решений – основной и наиболее популярный метод, при помощи которого можно найти оптимальное решение. Действительно, построение «дерева» решений позволяет наглядно продемонстрировать структуру данных и создать работающую модель классификации данных, какими бы громоздкими они не были.