

Большое значение в развитии экспериментальных психодиагностических методик имеют технические средства стимуляции, регистрации и обработки психодиагностической информации. Эти технические средства получили свое наиболее полное применение в современных высокопроизводительных компьютерах с их мощными операционными и изобразительными возможностями.
Воспроизведем процесс типичной процедуры «ручной» обработки данных психодиагностического тестирования.
После того, как испытуемый отдает психологу бланк с ответами на вопросы теста, психолог подсчитывает количество «попаданий» ответов в соответствии c диагностическим «ключом». После этого психолог с помощью таблиц или номограмм переводит определенное им количество в новое число – стандартизированную оценку. За такой простой на первый взгляд процедурой стоит кропотливая работа создателя психодиагностического теста. По-настоящему глубокий эмпирико-статистический анализ, обеспечивающий обоснованные, точные и надежные диагностические результаты, невозможен без применения современных компьютерных методов. Без этого анализа не обходится ни одна серьезная попытка конструирования или адаптации тестов. Рассмотрим методы, применяющиеся в конструировании психодиагностических тестов.
Метод главных компонент
Метод главных компонент был предложен Пирсоном в 1901 году и разработан Хоттелингом в 1933 году. Данный метод позволяет осуществить переход к новой системе координат y1,...,уn в исходном пространстве признаков x1,...,xn.
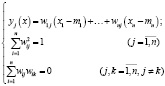 ,
,
где mi – математическое ожидание признака xi. Линейные комбинации выбираются таким образом, что среди всех возможных линейных нормированных комбинаций исходных признаков первая главная компонента у1(х) обладает наибольшей дисперсией.
Вычисление коэффициентов главных компонент wij полагается на умозаключение о том, что векторы wi=(w11, ..., wnl)’, ..., wp=(w1n, ... , wnn)’ являются собственными векторами матрицы S. Алгоритмы, отвечающие за выполнение метода главных компонент, входят практически во все пакеты статистических программ.
Факторный анализ
Факторный анализ ориентирован на объяснение имеющихся между признаками корреляций. Поэтому факторный анализ применяется в более сложных случаях совместного проявления на структуре экспериментальных данных тестируемого, а также для выделения группы диагностических показателей из общего исходного множества признаков.
Основное уравнение факторного анализа:
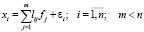 .
.
Значения каждого признака xi можно выразить взвешенной суммой латентных переменных fi, число которых меньше числа исходных признаков, и остаточным членом εi с дисперсией σ2(εi), действующей только на xi. Коэффициенты lij называются нагрузкой i-й переменной на j-й фактор или нагрузкой j-го фактора на i-ю переменную. В самой простой модели факторного анализа делается упущение о том, что факторы fj взаимно независимы и их дисперсии равны единице, величины εi тоже независимы друг от друга и от фактора fj. Максимально возможное количество факторов m при заданном числе признаков n определяется неравенством:
(n+m)<(n – m)2,
Чем больше значение суммы квадратов нагрузок, тем лучше описывается признак xi факторами fi. Основное соотношение факторного анализа показывает, что коэффициент корреляции любых двух признаков xi и хj можно выразить суммой произведения нагрузок некоррелированных факторов:
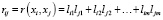 .
.
Некоторые являются сторонниками факторного анализа, некоторые его осуждают, но, как точно заметил В.В. Налимов, «У психологов и социологов не оставалось других путей, и они изучили эти два приема (факторный анализ и метод главных компонент)».
Метод контрастных групп
При использовании метода контрастных групп исходной информацией помимо таблицы с результатами обследования испытуемых является также «черновая» версия линейного правила вычисления тестируемого показателя. Эта версия может быть составлена экспериментатором, исходя из его теоретических представлений о том, какие признаки должны быть включены в линейную диагностическую модель.
Основой данного метода является гипотеза о том, что большая часть «черновой» версии диагностической модели подобрана или угадана правильно. То есть в правую часть уравнения уч = уч(х) вошло достаточно много признаков, согласованно отражающих тестируемое свойство. В то же время в этой версии определенную долю признаков составляет ненужный или вредный балласт, от которого необходимо избавиться.
В первую очередь назначаются исходные шкальные ключи wj для пунктов теста (дихотомических признаков) хj. Для каждого i-го испытуемого подсчитывается суммарный тестовый балл:
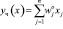 .
.
Как правило, абсолютные значения весов wj определяют приблизительно и часто берут равными единице. Поэтому направление
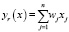
будет несколько отличаться от направления главной диагонали эллипсоида рассеивания у(х). Но если уч(х) правильно отражает диагностируемый признак, то на краях распределения суммарного балла можно выделить контрастные группы ω1 и ω2, в которые войдут объекты с минимальными погрешностями. Для нормального распределения обычно берут контрастные группы объемом 27 % от общего объема выборки, для более плоского – 33 %.
Следующий шаг заключается в определении степени связи каждого пункта с номером контрастной группы. Мерой этой связи служит коэффициент различения, который представляет собой разницу процентов какого-либо ответа на анализируемый пункт в полярных группах испытуемых. Наиболее часто используется коэффициент связи Пирсона φ, который затем сравнивается с граничным значением:
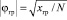 ,
,
где xгр – стандартный квантиль распределения x с одной степенью свободы.
Таким образом, мы видим, что без применения математических методов функционирование такого значительного в нашей жизни процесса, как конструирование психодиагностических тестов, невозможно.