

Проблема занятости – одна из наиболее обсуждаемых тем в рамках экономической дискуссии любой страны. Количество занятых в экономике во многом определяет темпы и характер её развития, ведь в конечном счёте её движущая сила – люди.
Целью нашего исследования является оценка взаимосвязи количества занятых и уровня развития экономики по субъектам Российской Федерации, проверка на однородность и рассмотрение различных способов приведения ряда к однородному в случае гетероскедастичности. В работе представлена оценка влияния количества занятых в регионах (фактор x) на валовый региональный продукт (фактор y). Основным источником данных для исследования послужила Федеральная служба государственной статистики. Информация о валовом региональном продукте, а также данные о численности занятых представлены по 83 субъектам на 2012 год.
Перейдём к оценке гетероскедастичности. С помощью регрессии построим остатки модели. Сумма остатков получается равна нулю. Далее построим диаграмму.
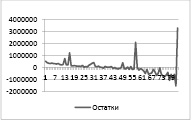
Диаграмма 1. Остатки модели регрессии
С помощью визуального анализа по Диаграмме 1 можно сделать вывод, что в данной модели присутствует гетероскедастичность остатков, так как наблюдаются систематические изменения в соотношениях между ŷi и квадратами ei2. Проверим наличие гетероскедастичности с помощью тестов.
I. Тест Голдфельда-Квандта. Рассчитываем F наблюдаемое по формуле:
Fнабл = SSmax / SSmin [4].
Сравниваем полученное значение с рассчитанным по формуле табличным значением
Fтабл(k1 = n1 – m; k2 = n – n1 – m)
где n1 – количество данных в первой выборке, m – количество рассматриваемых факторов, n – количество данных по всей выборке. По результатам проведённого теста получили следующие значения:
|
F набл |
13,49408 |
|
F табл |
1,694236 |
Так как наблюдаемое значение больше, чем табличное, то присутствует гетероскедастичность.
II. Тест ранговой корреляции Спирмена. Значимость коэффициента ранговой корреляции Спирмена вычисляется по формуле:
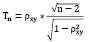 ,
,
где 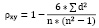
Одновременно с этим считаем и табличное значение:
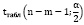
По результатам проведённого теста получили следующие значения:
|
Tнабл |
2,677917 |
|
Ттабл |
1,989686 |
Так как наблюдаемое значение больше табличного, то присутствует гетероскедастичность.
III. Тест Глейзера. В качестве фактора возьмём значения объясняющего фактора х (численность занятых). Строим вспомогательное уравнение регрессии изменяя значения γ (…-1; -0,5; 0,5; 1…), получаем несколько четыре модели. Если хотя бы в одной модели коэффициент β окажется значимым, то в модели присутствует гетероскедастичность.
Разберём алгоритм на примере для модели
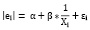
(то есть, при γ = – 1):
|
Tнабл |
-0,22pic5590395 |
|
Ттабл |
1,989686323 |
Так как наблюдаемое значение меньше табличного, то мы признаём статистическую незначимость коэффициента β. Расчёты показали, что коэффициент β статистически значим только для моделей, построенных при γ = 0,5 и при γ = 1. Это означает, что присутствует гетероскедастичность.
IV. Тест Уайта. Метод заключается в том, чтобы определить общую значимость уравнения с помощью сравнения критерия χ2 и тестовой статистики U = nR2, где n – число наблюдений. Применим к данному уравнению инструмент «Анализ данных – Регрессия» и выясним значение R2 = 0,834195404. Легко подсчитать, что:
|
U |
69,23821853 |
|
χ20,05;2 |
5,991464547 |
Так как тестовая статистика U больше критерия χ2, то мы отвергаем гипотезу о гомоскедастичности и говорим о наличии гетероскедастичности.
Все четыре выполненных теста подтвердили нашу первоначальную теорию, основанную на присутствии в выборке гетероскедастичности. Причинами такого явления могут являться следующие признаки:
1. Неоднородность исследуемых объектов (что как раз наблюдается в данной выборке);
2. Характер наблюдений (например, данные временного ряда).
Одним из серьёзных последствий гетероскедастичности является неточная оценка параметров модели. Методы избавления от гетероскедастичности мы выполним по следующим направлениям: кластеризация данных для борьбы с неоднородностью объектов и применение обобщённого метода наименьших квадратов для получения более точной оценки данных.
Был проведён кластерный анализ в программе VSTAT. В результате анализа были выявлены пять групп. Что не удивительно, в пятой группе оказался только один субъект, и им стал город федерального значения – Москва, с самым наибольшим показателем валового регионального продукта, а также с наибольшей численностью занятого населения. В четвёртый кластер тоже входит лишь один показатель, и это – данные по Ханты-Мансийскому автономному округу-Югра. Для дальнейшего избавления от гетероскедастичности мы будем использовать только первый кластер с более однородными данными, который содержит 61 субъект. Так же, как и для всей выборки, построим диаграмму остатков для визуального анализа.
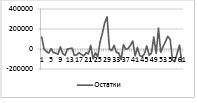
Диаграмма 2. График остатков модели (первый кластер)
Визуальный анализ показывает, что колебания всё равно остались, однако чтобы лучше понять, поможет ли нам такое разделения на группы убрать гетероскедастичность, необходимо выполнить проверку. Тест Голдфельда-Квандта, а также тест ранговой корреляции Спирмена показали присутствие гетероскедастичности. Раз не получилось избавить от гетероскедастичности с помощью кластеризации, то можно попробовать хотя бы улучшить, сделать более точными оценки параметров регрессии с помощью обобщённого метода наименьших квадратов. Рассчитаем среднеквадратические отклонения Saj для параметров модели регрессии, которые будут считаться оценками модели. Расчёт производим по формулам:
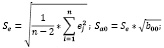 .
.
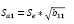
Для наилучшего восприятия приведём посчитанные оценки в конце данных вычислений. Проведём оценку вектора A с помощью обобщённого метода наименьших квадратов. Приведём оценки модели для первого кластера, а также для модели, рассчитанной с помощью обобщённого метода наименьших квадратов.
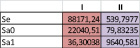
Сравним статистические характеристики уравнений регрессий, полученных с помощью МНК и ОМНК. Можно заметить, что второе уравнение имеет более точную оценку a0, однако вторая оценка a1 менее точна.
Заключение
Вывод: ни кластерный анализ, ни обобщённый метод наименьших квадратов не помогли уйти от гетероскедастичности, а также не помогли улучшить оценки регрессии. Это может быть связано с тем, что данные, отобранные для исследования, первоначально слишком разнородные, так как все субъекты Российской Федерации слишком разные по количеству занятых и по характеру и объёму производства. Оказалось, что не все модели можно избавить от гетероскедастичности и привести к однородности. Проведём сравнительный анализ регрессионных статистик до проведения кластерного анализа, а также после проведения процедуры в программе VSTAT с помощью метода наименьших квадратов, а также с помощью обобщённого метода наименьших квадратов.


Рис. 1. Регрессионная статистика после кластеризации
Рис. 2. Регрессионная статистика до кластеризации
Стоит отметить, что показатели, приведённые в таблицах не дают хорошего представления о единственной подходящей модели. Поэтому воспользуемся тестом Чоу для выяснения, можно ли нам использовать одну модель для всех данных, либо же надо применять различные модели для разных подвыборок. Первоначально выдвинута гипотеза об однородности двух подвыборок и об использовании общей модели. Для регрессионного анализа используем подвыборку, состоящую их наблюдений первого кластера, а также вторую подвыборку из оставшихся данных. Также находим остатки. Полученные результаты приведены в таблице:
|
df |
||
|
Остатки общие |
81 |
2,89058E+13 |
|
Остатки 1 |
59 |
4,58676E+11 |
|
Остатки 2 |
20 |
2,38791E+13 |
На основе полученных данных рассчитываем Fнаблюдаемое с помощью формулы:

Также рассчитываем Fкритическое по формуле:
Fкрит. = FРАСПОБР(0.05; k + 1; n – 2k – 2).
Результаты проведённых вычислений представлены в таблице:
|
Fнабл |
7,413876 |
|
Fкрит |
3,11226 |
Наблюдаемое значение превышает критическое, это значит, что гипотеза от однородности подвыборок отвергается. В данном случае следует рассматривать отдельно первый кластер данных и остальные показатели. Итак, в данной работе не получилось привести данные к однородной выборке. Вероятнее всего, это произошло из-за того, что на валовый региональный продукт влияет множество факторов помимо экономических, которые невозможно охватить. Конечно, влияние численности занятых тоже очень важно. Ведь среди факторов ясно прослеживается тенденция: чем больше работающих, тем выше региональный продукт. Безусловно, данная проблема требует дальнейшего изучения и рассмотрения с помощью различных эконометрических методов.