

Введение. Анализируя статистику, можно отметить, что 2020 год стал годом глобальной информатизации всех сегментов человеческой деятельности, причиной такого роста потребности в развитии ИТ стала глобальная пандемия вируса COVID-19. Безусловно, среди ведущих проблем человечества стоит проблема образования в условиях полного или частичного карантина, что в свою очередь стало катализатором исследований того или иного вектора образовательного процесса в условиях пандемии. Осуществляя предварительный анализ исследований, можно отметить значительный рост количества научных публикаций об образовательном процессе на языках смешанного и дистанционного обучения, среди ведущих направлений исследований: разработка систем адаптивного тестирования обучающихся, использование автоматизированных систем обучения, процесс. Однако можно отметить, что образовательный процесс, особенно в среднем и профессиональном образовании, требует более универсального и удобного контакта при общении с преподавателем и создания условий для асинхронного общения. Предварительный анализ научных источников показал недостаточную изученность данного вопроса, что подтверждает актуальность нашего исследования. Анализ исследования и разработки рекомендаций по использованию систем персонализации и индивидуализации, с целью повышения качества учебного процесса позволил сформулировать тематику исследования и выбрать тематикой исследования персонализацию интерактивных цифровых медиа в образовательной среде путем внедрения технологии «повсеместных вычислений» в системы электронного образования.
Архитектура контекстного доступа
Термин «повсеместные вычисления» (ubiquitous computing) получил широкое распространение с момента его первого использования Марком Вайзером [12] в 1991 году. С тех пор он превратился в новую область исследований, целью которой является плавная цифровизация окружающей среды. Конечная цель повсеместных вычислений — ненавязчиво помогать людям в их повседневных задачах, тем самым делая процесс взаимодействия человека с компьютером максимально незаметным и удобным. Повсеместные вычисления обычно разделяют на три основные темы исследований [5]: естественные интерфейсы, контекстная осведомленность, приложения захвата и доступа (далее ПЗД).
В рамках нашего исследования наиболее целесообразным будет акцент внимания на вопросах контекстной осведомленности и приложениях ПЗД, в частности, в части персонализации и автоматизированной рекомендации мультимедийного контента, полученного из сред, оснащенных повсеместными вычислительными устройствами.
Как пример функционирования проблемы, можно выделить образовательную область с записью университетской лекции в аудитории, оборудованной электронной доской, микрофонами и видеокамерами. В таком сценарии за один сеанс захвата может быть записано несколько мультимедийных элементов: слайды с электронной доски, аудио-потоки с микрофонов и видео с камер. С другой стороны, в данной цепочке, пользователи заинтересованы в доступе к соответствующей части информации, нацеленной на определенные медиа-элементы, ориентированные на учет и удовлетворение конкретных потребностей и вкусов. К таким функциям можно отнести: рекомендацию контента, ранжирование, персонализацию, поддержку предпочтений.
Практический пример этих требований может быть представлен студентом, желающим найти какой-либо материал, связанный с экзаменом. Основываясь на его учебном контексте во время периодов активности (например, место доступа, доступное время для учебы и функции устройства), система может предложить ему персонализированный доступ, предоставляя интерфейс, который указывает непосредственно на содержание его следующего запланированного экзамена. Более того, персонализация в этом случае может выходить за рамки, адаптируя уже отфильтрованный контент к более конкретным ограничениям, например, исключая аудиоконтент, в связи с активностью пользователя в общественных местах с неподключенными наушниками, или показывая только отснятые слайды (без видео) из-за Интернет-соединения с низкой пропускной способностью.
В работе мы представляем архитектуру контекстного доступа (АКД), которая сочетает в себе: контекст доступа, пользовательские предпочтения и ограничения представления устройства.
АКД позволяет рекомендовать контент, ранжировать и персонализировать интерактивные мультимедийные презентации, созданные в оборудованной аудитории.
Приложения ПЗД обычно структурируются в соответствии с четырьмя этапами, предложенными Г. Абаудом и др. [7]:
Этап1.Предпродакшн: подготовка контента для системы захвата.
Этап2.Запись в реальном времени: запись медиапотоков с устройств захвата;
Этап3.Постпродакшн: синхронизация и интеграция медиапотоков;
Этап4.Доступ: пользователи просматривают мультимедийные документы.
По мнению Дж. Кинца [9], процесс доступа в приложениях ПЗД часто остается второстепенным, а усилий, вложенных в их разработку, недостаточно. Если этап доступа разрабатывается с упором на пользователей, они будут более заинтересованы в визуализации захваченного контента. Таким образом, хорошие возможности поиска, рекомендаций и персонализации являются ключом к успеху любой системы ПЗД.
Контекст доступа пользователя
В литературе имеется множество определений контекста. Среди первых, кто использовал термин «контекстно-зависимый» были Б. Шилит и М. Теймер [1] в 1994 году, согласно их трактовке, контекст может быть определен некоторыми переменными, такими как местоположение, окружающий социум, а также близлежащие объекты и процессы их изменения. Другие авторы понимают контекст аналогичным образом, удаляя или добавляя некоторые переменные, такие как время суток, температура, время года и другие.
Г. Абауд и др. [6] определяют контекст как любую информацию, описывающую объект. Для них сущностью может быть человек, место или объект. Те же авторы также определяют «контекстно-зависимый» как использование контекста для предоставления релевантной информации и/или услуг пользователям.
В отечественной литературе термин «контекст» чаще используется в литературном аспекте, однако в некоторых источниках указывается иное виденье, в котором контекст трактуется, как:
‒ совокупность фактов и обстоятельств, в окружении которых происходит какое-либо событие, существует какое-либо явление, какой-либо объект;
‒ совокупность значений регистров, состояний флагов и т. п. процессора в ходе выполнения программного процесса.
В мобильных и повсеместных вычислениях контекст пользователя быстро меняется. Многие приложения используют переменные контекста для настройки представления контента пользователям в соответствии с их текущей ситуацией (поисковые системы и агенты, алгоритмы учета предпочтений в электронной коммерции или сфере услуг). Таким образом, контекст необходим для обеспечения лучшего взаимодействия с пользователем при извлечении ранее захваченного контента.
К. Труонг, в своей работе [10], раскрыл минимальный набор вопросов, которые необходимо учитывать при разработке функций контекстно-зависимого управления для приложений ПЗД:
1. Кто ваши пользователи?
2. Что захватывается и доступно?
3. Когда происходит захват и доступ?
4. Где происходит захват и доступ?
5. Как выполнять задачи захвата и доступа?
Основываясь на оригинальном виденье К. Труонга, мы рассмотрели 7 измерений, которые необходимо учитывать при моделировании пользовательского контекста в приложениях ПЗД для образовательных сред:
1. Тип устройства, например, «Настольный компьютер», «Планшет» или «Смартфон»;
2. Пропускная способность устройства, измеряемая в кбит/с;
3. Разрешение экрана устройства, например, «до 240х360», «до 800х600» и др.;
4. Дата и время доступа;
5. Время беспрерывного взаимодействия пользователя для просмотра отснятого контента, например, «до 15 минут», «до 30 минут», «до 60 минут» или «более 60 минут»;
6. Место подключения, где пользователь осуществляет доступ, например, «Университет», «Дом» или «Работа»;
7. Причина подключения, по которой пользователь заходит в систему, например, «Обычные занятия», «Тест», «Быстрый просмотр» или «Пропущенный урок».
Пользовательские настройки
Пользовательские предпочтения — это набор личных предпочтений, которые в нашем случае используются для рекомендации захваченного контента, который лучше соответствует потребностям пользователя. Студент, который хочет, чтобы лекции были связаны с тестом, был бы хорошим примером такого спроса. В зависимости от его контекста доступа система может предоставить ему персонализированный доступ, представляя контент, непосредственно связанный с предметом следующего запланированного теста. Существует множество алгоритмов и методов, которые имеют дело с пользовательскими предпочтениями [8], [13], [14]. Наша цель не в том, чтобы предложить конкретный алгоритм или метод, а в том, чтобы поддержать другие в качестве альтернативных механизмов для сбора информации о пользователе и определения его/ее личных предпочтений.
Ограничения представления
Начало карантинных ограничений и СВО привело к возникновению проблем с потоковым подключением студентов к учебному процессу в реальном времени, о чем пишут отечественные ученые Круглик В.С. [11], Букреев Д.А. [4], Тухтасинов, И.[16], Автушенко, И. А., Соловьева, М. В. [15] и другие. Представьте себе устройство пользователя, подключенного к сети с низкой пропускной способностью, или студента, который хочет сделать быстрый обзор перед предстоящим занятием. В обоих случаях потоковое видео не рекомендуется. Таким образом, захваченный контент должен быть представлен персонализированным образом, например, только слайды лекции, для быстрой загрузки и основных функций просмотра, без видеопотока.
Другой ситуацией может быть, например, учащийся, использующий мобильное устройство с маленьким экраном. Возможно, этот студент не очень хорошо увидит подробные слайды лекций, в этой ситуации система могла порекомендовать только аудиозапись лекции.
Это примеры некоторых ограничений представления, которые могут быть наложены в отношении контекста доступа пользователя или даже предпочтений пользователя. Эти ограничения не являются строгими в том смысле, что они лишь предлагают возможности персонализации для представления извлеченного мультимедийного контента. Это достигается путем ранжирования возможных макетов, и пользователь может свободно выбирать тот, который лучше соответствует его потребностям, чтобы визуализировать лекцию.
Детальная архитектура
Все модули предлагаемой нами архитектуры слабо связаны, что означает, что архитектура была разработана таким образом, чтобы допускать различные реализации алгоритмов и/или методов рекомендаций и персонализации. Для достижения основных целей персонализированной образовательной среды была выбрана архитектура, состоящая из 4 модулей:
1. Модуль интерфейса (Context Collection & Inference Module).
2. Модуль обработки ограничений (Constraints Handling Module).
3. Модуль обработки запросов (Query Handling Module).
4. Модуль представления (Presentation Module).
Отдельно добавляются два репозитория: репозитории лекций (Lectures Repository) и репозиторий таблиц стилей (Stylesheets Repository).
Исходя из архитектуры, общий алгоритм работы выглядит так:
1. Модуль интерфейса, отвечает за сбор пользовательского контекста и выполнение некоторых основных выводов по нему. В зависимости от того, насколько сложны сенсорные возможности приложения, контекст может собираться автоматически, явно информироваться пользователем. После того, как контекст установлен, он содержит первичную единицу информации, проходящей через АКД. Затем на основе контекстной информации выбираются предпочтения пользователя и ограничения представления. Два соответствующих репозитория хранят настройки и ограничения отдельно.
2. Как только система получает полную информацию о пользовательском контексте, предпочтениях и всех соответствующих ограничениях представления, модуль обработки ограничений, обрабатывает ограничения на основе пользовательского контекста и генерирует ранжирование представления. Здесь снова к ограничениям могут быть применены многие алгоритмы ранжирования представления.
3. 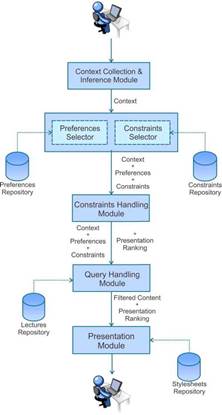
Кроме того, на основе контекста, предпочтений и ограничений пользователя модуль обработки запросов отвечает за переписывание запроса в базе данных, чтобы выбрать лучшие результаты контента для пользователя. Этот модуль ищет лекции в репозитории лекций, в результате чего отфильтровывается мультимедийный контент.
4. В завершении, модуль представления отвечает за правильное представление набора результатов пользователю. Этот модуль извлекает макеты презентаций из репозитория таблиц стилей и создает рейтинг, тем самым сортируя интерфейсы визуализации в соответствии с потребностями пользователя. Однако пользователь волен выбирать альтернативные варианты визуализации лекции.

Архитектуру контекстного доступа можно представить в виде схемы (рис.1). В рамках архитектуры, хранение, доступ и расширение мультимедийного контента в аудитории происходит в оборудованной электронной доской, микрофонами, камерами и проекторами. Медиапотоки с каждого устройства захватываются специализированными программными компонентами, а затем интегрируются и синхронизируются, создавая гипермедиа-документы в различных форматах представления. Построенная на платформе Moodle АКД для персонализации контента, позволяет настраивать представление захваченного контента в соответствии с предпочтениями и контекстом доступа каждого учащегося.
Система Moodle была выбрана в связи с результатами анализа актуальности и распространения открытого программного обеспечения для реализации электронного образования на территории стран СНГ, а также в связи с его возможностями постоянного развития, расширения функционала и модульнуй структурой, о чем раскрыто в работах [2-3].
Moodle помогает преподавателям с помощью вездесущих вычислительных ресурсов, не меняя обычной динамики учебной группы, в то время как учащиеся получают более поздний доступ ко всей информации, представленной во время занятий.
Работа системы будет требовать проведения ряда организационных мероприятий:
Подготовка к производству. В Moodle этап подготовки отвечает за настройку контента, который будет захвачен. На этом этапе через веб-интерфейс преподаватель регистрирует всю информацию, относящуюся к лекции. Такая информация разделена на три категории: (обязательная) основная информация, дополнительные данные (необязательная метаинформация) и само содержание лекции. Первая категория, базовая информация, хранится в реляционной базе данных, содержащей ссылки на другую информацию. Вторая категория, дополнительные данные, классифицируется и организуется с использованием расширений на основе метаданных. В третьей категории контент упакован в один файл, состоящий из слайдов в форматах pdf, ppt или pptx. Специализированный компонент отвечает за преобразование этого файла в пользовательский шаблон, распознаваемый системой захвата.

Живая запись. 
Одна из основных задач при разработке приложения ПЗД — сделать фазу записи в реальном времени прозрачной для вовлеченных пользователей. Процесс захвата должен быть максимально ненавязчивым, с минимальными изменениями в распорядке инструктора.
Фаза записи в реальном времени происходит, когда лекция представляется студентам в аудитории. Вначале инструктор обращается к веб-интерфейсу, чтобы выбрать необходимые настройки записи, и его содержимое автоматически загружается на электронную доску. На рис. 2 показан пример оборудованной аудитории с электронной доской, видеокамерой и проекторами для достижения поставленной задачи. Преподаватель может взаимодействовать с электронной доской, как если бы он использовал традиционную доску или меловую доску. Все штрихи, написанные на поверхности электронной доски, проецируются на второй, более крупный экран для облегчения просмотра учащимися.
Послепроизводственный этап. Фаза постпродакшна начинается сразу после завершения записи в реальном времени. На этом этапе клиентское приложение интегрирует все захваченные медиапотоки, синхронизирует их и создает документы для представления пользователю. Обычные форматы представления включают HTML для веб-визуализации.
Доступ. Этап доступа состоит из представления захваченного контента учащимся. Moodle использует наш подход АКД для создания ориентированного на пользователя, персонализированного доступа, который побуждает студентов визуализировать и взаимодействовать с полученными презентационными документами. Параметры место подключения, причина подключения и время беспрерывного взаимодействия пользователя указываются пользователем в явном виде, другие определяются системой автоматически.
Для обработки пользовательских предпочтений АКД использует CPrefSQL [13], расширение SQL, созданное для поддержки запросов контекстных предпочтений. Синтаксис CPrefSQL позволяет нам выражать условные предпочтения с помощью качественного подхода. Ограничения представления обеспечивают персонализацию контента, влияя на способ просмотра контента и то, какие медиа должны быть представлены в соответствии с контекстом пользователя. Например, если студент использует смартфон в спортзале, возможно, было бы лучше показать ему аудиозапись лекции, а не слайды или видео лекции.
Ограничения хранятся в виде XML-документов. Сначала система определяет ограничения по умолчанию, применяемые ко всем пользователям. По мере использования системы пользователь может определять свои собственные ограничения, которые добавляются к ограничениям по умолчанию или заменяют их. Преподаватель также может зарегистрировать календарь для каждого курса с датами экзаменов и заданий. Студенты видят эти даты на домашней странице курса. Такая информация используется для рекомендации контента. Например, учащийся не заходит в систему неделю, а затем входит в систему за день до запланированного теста; система может предложить ему сводку с уроками, оцененными инструктором как важные для этого теста. Рекомендуемый просмотр содержимого не является принудительным, и учащийся также может перечислить содержимое курса в хронологическом порядке или по названию.
АКД поддерживает реализацию ранжирования представления многими способами. Здесь он был реализован с использованием алгоритма средневзвешенного значения для вычисления сходства контекста пользователя. Для каждого ограничения представления RGR вычисляет:
Score(Ri, c) = E wd * simd(Ri(d),c) deD,
где R - набор ограничений представления; D - параметры контекста пользователя, c - экземпляр пользовательского контекста; wd - вес измерения d; simd - функция подобия размерности d между ограничением R и контекстом c.
Все параметры контекста имеют определенную функцию подобия, которая вычисляется независимо. Некоторые из них являются логическими функциями, например, измерение причины представляет собой простое сравнение между значением ограничения и значением контекста, т. е. было ли оно выбрано или нет (1 или 0). Напротив, другие функции рассчитываются в вероятностном диапазоне, действительном числе от 0 до 1. Кроме того, каждое измерение контекста имеет свой вес с учетом текущего ограничения.
Выводы. Разработанная АКД может улучшить существующие автоматизированные приложения для захвата мультимедиа, где контекст и предпочтения пользователя имеют значение для создания персонализированных представлений медиа. Он поддерживает рекомендацию контента и ранжирование по дизайну и является полезным инструментом для вездесущих образовательных сред. Состоящий из слабо связанных компонентов, которые можно заменять в соответствии с потребностями приложения, АКД допускает расширение и допускает различные реализации для каждого модуля (например, алгоритм ранжирования).
Нами был разработан практический алгоритм внедрения АКД в электронную систему учебного процесса, что позволит преподаватели проводить лекции в интерактивной форме, в то время как студенты извлекают выгоду из большого объема захваченного контента для изучения с форматами презентации, адаптированными к их контексту доступа, предпочтениям и ограничениям устройства.
Разработанная система требует педагогического внедрения для определения уровня влияния на учебный процесс, что станет тематикой наших дальнейших исследований для дальнейшего улучшения и разработки методов интеллектуального анализа для автоматического определения пользовательских предпочтений.
Библиографическая ссылка
Букреев Д.А., Барановская В.С. ПЕРСОНАЛИЗАЦИЯ ИНТЕРАКТИВНЫХ ЦИФРОВЫХ МЕДИА В ОБРАЗОВАТЕЛЬНОЙ СРЕДЕ // Международный студенческий научный вестник. – 2023. – № 2. ;URL: https://eduherald.ru/ru/article/view?id=21242 (дата обращения: 16.04.2024).