

Введение
В течение последних десятилетий было предложено несколько методов преобразования голоса, таких как кодовая книга, дискретная функция преобразования, GMM и ANN (искусственная нейронная сеть). В методе сопоставления кодовой книги применяется технология кластеризации спектральных параметров исходного и целевого голоса, а функция отображения получается из двух результирующих кодовых книг. Одним из основных недостатков данного метода является то, что преобразованные параметры имеют ограниченное число, что приводит к серьезному ухудшению качества речи. Далее, чтобы заменить метод кодовой книги сопоставления было предложено дискретное преобразование с использованием кусочно-линейной функции. Однако, использование этой технологии приводило к разрывам в преобразованной речи. В методе VC на основе GMM преобразование устанавливается на основе непрерывных вероятностных функций. Экспериментальные результаты показывают, что полученные результаты намного лучше, по сравнению с другими предыдущими методами трансформации. Метод ANN как непрерывной и нелинейной функции также исследован, и было доказано, что результаты, сопоставимые с результатами метода GMM, могут быть достигнуты, но есть несколько основных недостатков, таких как большая вычислительная нагрузка, множественные локальные минимумы в зависимости от минимизации эмпирического риска и связанной с проблемой преодоления. В настоящий момент GMM является самым популярным и хорошо зарекомендовавшим себя методом преобразования голоса. Было предложено много улучшенных методов на основе GMM, таких как метод GMM и DFW (метод динамической деформирования частоты), метод GMM и MAP (максимальный апостериорный метод) и GMM с использованием метода генерации параметров ML (максимального правдоподобия). Эти методы избегают проблем разрыва преобразованной речи. В отличие от традиционных методов GMM или ANN, SVR-подход может отображать нелинейную зависимость между исходным и целевым голосами, ему требуется меньше данных для обучения, и он менее подвержен локальным минимумам. Таким образом, предлагается гибридный метод преобразования голоса на основе SVR и GMM, в котором SVR-сопоставление выполняется вместо линейной регрессии в каждом компоненте GMM.
Базовый GMM на основе спектрального преобразования
Существует два основных подхода преобразования голоса, основанных на GMM, первый - LSE (метод наименьшего квадрата) и JDE (совместная оценка плотности). Эти методы показывают эквивалентную производительность, которая выбирается в качестве базовой линии метода преобразования голоса на основе гибридного SVR и GMM.
Пусть 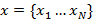 и
и 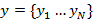 - последовательности спектральных параметров исходного и целевого голоса соответственно, где
- последовательности спектральных параметров исходного и целевого голоса соответственно, где 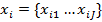 и
и 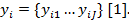 Последовательность x выровнена относительно y, чтобы получить пару параллельных последовательностей
Последовательность x выровнена относительно y, чтобы получить пару параллельных последовательностей 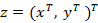 (где надстрочный индекс T обозначает транспонирование), которая используется для обучения совместных параметров GMM (α, μ, Σ). GMM можно записать в виде суммы M гауссовых компонент, которая принимает вид:
(где надстрочный индекс T обозначает транспонирование), которая используется для обучения совместных параметров GMM (α, μ, Σ). GMM можно записать в виде суммы M гауссовых компонент, которая принимает вид:
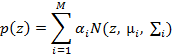 (1)
(1)
где 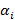 обозначает предыдущую вероятность i-го компонента и удовлетворяет
обозначает предыдущую вероятность i-го компонента и удовлетворяет 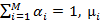 и
и 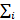 - средние и
- средние и  ковариационные матрицы i-го компонента [2]. Функция преобразования и минимизации средних квадратичных ошибок между преобразованной и целевой речью, может быть записана как:
ковариационные матрицы i-го компонента [2]. Функция преобразования и минимизации средних квадратичных ошибок между преобразованной и целевой речью, может быть записана как:
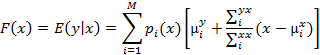 (2)
(2)
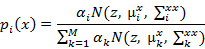 (3)
(3)
где, 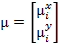 и
и 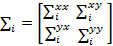 и pi (x) - вероятность x, принадлежащая i-му компоненту.
и pi (x) - вероятность x, принадлежащая i-му компоненту.
Предлагаемые гибридные методы SVR и GMM
Рассмотрим новый гибридный метод преобразования голоса на основе SVR и GMM. SVR применяется в каждом компоненте GMM, он радикально отличается от традиционных методов GMM или ANN. Данный метод выполняет идеальное нелинейное отображение между исходным и целевым голосами и может эффективно избегать проблемы с перегрузкой и всегда находит глобальные минимумы [3]. В отличии от традиционного одномерного выходного значения, SVR предлагает многомерное преобразование голоса [4]. Функция преобразования представляет собой регрессию в i-м компоненте и задается выражением:
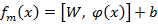 (4)
(4)
где 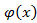 - нелинейная функция отображения из низкоразмерного пространства в более высокое,
- нелинейная функция отображения из низкоразмерного пространства в более высокое, 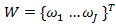 и
и 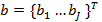 определяют два J-мерных регрессора в верхнем размерном пространстве. Функция регрессии может быть получена путем оптимизации:
определяют два J-мерных регрессора в верхнем размерном пространстве. Функция регрессии может быть получена путем оптимизации:
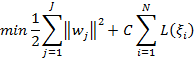
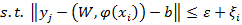
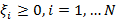 (5)
(5)
Здесь C - штрафной коэффициент, ε и 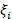 - переменные, которые показывают ошибками на обучающих точках, а L() обозначает функцию стоимости [5]. Вместо гиперкубической интенсивной зоны, используемой в SVR на основе ε, принимается гиперсферическая нечувствительная зона, чтобы справиться с многомерным выходом, а также метод IRWLS (итеративный реверсифицированный наименьший квадрат) используется для решения уравнения Лагранжа следующим образом:
- переменные, которые показывают ошибками на обучающих точках, а L() обозначает функцию стоимости [5]. Вместо гиперкубической интенсивной зоны, используемой в SVR на основе ε, принимается гиперсферическая нечувствительная зона, чтобы справиться с многомерным выходом, а также метод IRWLS (итеративный реверсифицированный наименьший квадрат) используется для решения уравнения Лагранжа следующим образом:
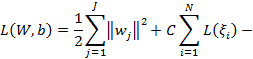
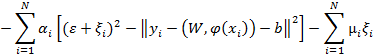 (6)
(6)
где 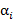 и
и 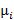 - множители Лагранжа. Неизвестные параметры
- множители Лагранжа. Неизвестные параметры 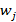 и
и 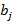 будут вычисляться в каждом измерении. Таким образом, функция преобразования голоса на основе GMM может быть модифицирована как:
будут вычисляться в каждом измерении. Таким образом, функция преобразования голоса на основе GMM может быть модифицирована как:
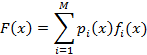 (7)
(7)
Как известно, правильный выбор ядра является ключом к производительности SVR. RBF (радиальная базисная функция) и полиномиальная функция являются двумя типичными методами ядра. RBF обладает лучшей интерполяционной характеристикой, в то время как полиномиальная функция 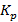 показывает лучшую экстраполяционную способность. Для повышения эффективности преобразования вводится смешанное ядро:
показывает лучшую экстраполяционную способность. Для повышения эффективности преобразования вводится смешанное ядро:
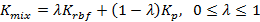 (8)
(8)
Вес λ изменяется от 0 до 1 при размере шага 0,05.
Преобразование F0
Типичный метод преобразования F0 основан на GMM, который описывается формулой 2. Многие исследования показали взаимосвязь между спектральными параметрами и F0. Совместное GMM используется для моделирования F0 и спектральных характеристик [6]. Предсказание F0 из MFCC (частотного векторного кепстрального коэффициента), где используются методы GMM и HMM (скрытая марковская модель) указывает на то, что эти методы могут достичь удовлетворительных результатов, как прогнозировалось, но все же существуют некоторые недостатки: линейность отношений между спектральными параметрами и F0, а также потребность в большом объеме данных на этапе обучения [7]. Таким образом применяется метод SVR, который делает нелинейное сопоставление, используя меньше данных для обучения, вследствие чего F0 прогнозируется по спектральным параметрам. В зависимости от традиционных методов преобразования F0, для процесса обучения необходимы только целевые функции. Модификация F0 выполняется следующим образом:
Шаг 1. На этапе тренировки, последовательности спектральных параметров и 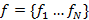 целевой речи вычисляются с использованием метода STRAIGHT.
целевой речи вычисляются с использованием метода STRAIGHT.
Шаг 2. Затем, алгоритм EM (ожидание максимизации) используется для моделирования y и f в совместном GMM. В каждом компоненте GMM функция преобразования обучается между y и f, используя SVR на основе ε со смешанным ядром.
Шаг 3. На этапе преобразования, F0 оценивается по преобразованным спектральным параметрам с использованием обучаемых функций преобразования SVR.
Преобразование голоса на основе непараллельных данных
Ранее обсуждавшиеся методы преобразования голоса были основаны, главным образом, на параллельных данных для обучения, которые требуют одинаковые исходные и целевые высказывания. Недавно были исследованы подходы с использованием непараллельных данных [8], они могут получить удовлетворительные результаты, но все еще нуждаются в некоторой предварительной информации от функции отображения между исходными и целевыми голосами, что не всегда возможно в реальных приложениях. В данной статье применялся метод SVR для записи специфичной голосовой информации, который не нуждается в какой-либо предварительной голосовой информации источника и позволяет делать преобразование голоса от произвольного источника до цели. Идея стимулируется специфическим отображением для распознавания речи [9]. Пусть L обозначает лингвистическую информацию, а LS соответствует лингвистической и говорящей информации. Функция отображения Q(L) вычисляется для получения отношений между L и LS и вычисляется с использованием метода LSE на данных обучения, чтобы минимизировать квадратичные ошибки:
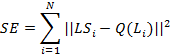 (9)
(9)
Предполагая, что m и n являются порядками для L и LS, которые трудно определить. Низкий порядок анализа LP (линейный предсказательный) (m: 4~8) может грубо фиксировать лингвистическую информацию говорящего, тогда как более высокий порядок LP (n:> 12) может захватывать как лингвистическую, так и динамическую информацию [10]. На рисунке 1 показана блок-схема процесса обучения SVR на основе голосового преобразования с использованием специфичной информации, и метод VTLN (нормализация длины голосового тракта), поскольку модуль предварительной обработки принимается для извлечения лингвистической информации.
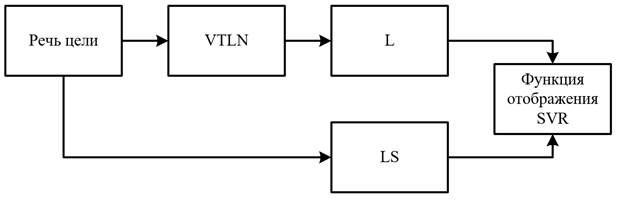
Рис. 1. Структура обучения системы преобразования голоса, использующая информацию о голосе.
Заключение
В данной статье был дан обзор нового метода преобразования голоса, основанного на гибридных SVR и GMM, который показывает лучшую производительность, чем базовый метод GMM. В статье также предлагается новый подход преобразования F0 для повышения производительности преобразования голоса, который требует изучения только специфической информации целевой речи. Объективные и субъективные экспериментальные результаты подтверждают эффективность предлагаемых методов, но идеальный метод преобразования голоса должен учитывать и другие аспекты, такие как длительность, скорость и стиль речи.
Библиографическая ссылка
Романов А.К., Белов Ю.С. ПРЕОБРАЗОВАНИЕ ГОЛОСА НА ОСНОВЕ ГИБРИДНОГО SVR И GMM // Международный студенческий научный вестник. – 2018. – № 6. ;URL: https://eduherald.ru/ru/article/view?id=19246 (дата обращения: 23.04.2024).