

Большинство современных систем отбора информации из текстов построены для решения определенных задач, сформулированных заранее. Нет системы, которая была бы рассчитана на максимальное решение задачи извлечения – полный синтаксический анализ, семантический анализ произвольного текста и получение всей информации, содержащейся в этом тексте. Любая задача для системы получения данных из текста может быть сформулирована в диапазоне от минимальной до максимальной.
Постановка проблемы
Целью данной статьи является исследование алгоритмов семантического преобразования поисковых запросов и разработка алгоритма для повышения их эффективности.
Объектом данного исследования являются алгоритмы интеллектуального анализа данных.
Предметом исследования является эффективность алгоритмов интеллектуального анализа содержания Web-ресурсов.
Актуальность статьи заключается в необходимости повышения эффективности методов извлечения знаний на основе информации, которая может извлекаться из распределенных разносторонних источников, что позволит интеллектуализировать Web-контент, дополнив содержание Интернет-ресурсов такими формальными описаниями, которые предоставят возможность интеллектуальным программам или агентам автоматически убеждаться в достоверности определенного контента.
Обзор существующих методов и программных решений семантичкого преобразования поисковых запросов
Одним из методов семантического преобразования поисковых запросов является сравнение всех контекстов, в которых слова или группы слов употребляются, и контекстов, в которых они не используются, что позволяет сделать вывод о степени близости содержания этих слов или групп слов.
Впервые метод семантического анализа был описан в работе «An Introduction to Latent Semantic Analysis «Landauer, Т.K., Foltz, P., and Laham, D. в 1998 году и затем развит в работах Scott Deerwester, Susan Duniais, George Furnas [3].
На данный момент лидером в области применения семантического анализа на практике является компания Pearson Knowledge Technologies. Их коммерческие продукты позволяют убедиться в эффективности метода семантического. Однако, конкретные алгоритмы реализации этого метода не опубликованы, поскольку это является коммерческой тайной, поэтому очень важной частью работы является создание программного обеспечения, которое позволит воспроизвести и проверить результаты работы алгоритмов семантического анализа.
Рассмотрим наиболее распространённые программные продукты для осуществления преобразования поисковых запросов [1]:
ConceptNet – семантическая нейронная сеть для понимания текста, написанного человеком;
FrameNet – это лексикографический онлайн ресурс, фундаментом которого является идея «фреймовой сементики».
WordNet – онлайн семантическая сеть с использованием различных связей слов: лексической, антонимической, контекстной и другими.
Математическое описание алгоритма поиска значимой информации
Представление слова и абзаца с помощью алгоритма семантического моделирует восприятие текста человеком (рис. 1). Например, с его помощью можно оценить эссе на соответствие теме или сравнить содержание отрывков текста.
Результаты метода достаточно достоверно отражают смысловые корреляции между словами и отрывками.
В качества начальных данных в общей основе алгоритмов семантического анализа используется частота нахождения каждого слова отдельно в тексте, а не частота нахождения каждой фразы.
К примеру, запрос «Apple computer» будет интерпретирован как принадлежность к компьютерной компании Apple, поэтому среди результатов будут документы, которые описывают технологии этой компании (даже если эти документы не содержат слов «Аррlе» или «computer»).
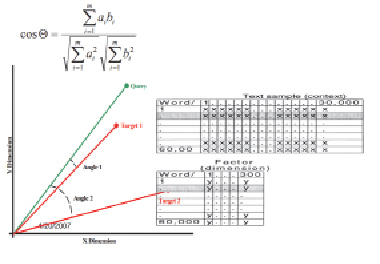
Рис. 1. Алгоритм семантического преобразования поисковых запросов
Пусть столбцы матрицы будут означать тексты, а строки – слова. Только элементы матрицы представляют собой количество нахождений конкретного слова в данном тексте. Именно такой подход и является стандартным для семантических моделей.
Итак, матрица отражает связи между словами и текстами. При анализе текстов возникает две проблемы:
• синонимия – когда разные слова обозначают одно и то же понятие;
• полисемия – когда одно и то же слово или несколько слов могут означать различные понятия.
Разработка алгоритма для повышения эффективности семантического преобразования поисковых запросов
На основе алгоритмов семантического анализа можно реализовать два варианта поиска. Первый, более классический, то есть пользователь вводит поисковый запрос, обычно это определенные ключевые слова или фразы, и как результат поиска получает документы, отсортированные в порядке релевантности запросу. Второй вариант реализует поиск похожих текстов. На вход пользователь подает документ, а в результате получает документы, которые похожи на исходный. Поиск, по ключевым словам, происходит среди файлов, которые находятся в определенном каталоге. По этим файлам строится матрица применяемости, но перед этим слова обрабатываются, чтобы уменьшить размерность матрицы.
Понятие «полноты» при отборе информации показывает отношение числа релевантных документов к числу всех найденных документов. В свою очередь «точность» определяется отношением числа найденных релевантных документов к общему числу релевантных документов. Для одновременного учета полноты и точности существует их комбинация (1), которая называется F-показатель и имеет следующий вид [2]:
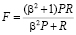 , (1)
, (1)
где P – точность; R – полнота; β – коэффициент баланса между оценками.
Если β = 1, то оба показателя имеют равный вес.
Все слова проверяются на принадлежность к так называемому списку «стоп-слов», наиболее часто встречающихся во всех возможных текстах (не только среди тех, по которым будет осуществляться поиск). Они никоим образом не будут отличать документ, текущий от других релевантных.
В результате, после обработки матрицы применяемости, на конвейер анализатора попадают словоформы без суффиксов и окончаний, что дает возможность не учитывать род и падеж слов (рис. 2).

Рис. 2. Отбор информации из объявления о семинаре
Заключение
Описаны алгоритмы и существующие программные решения первичной обработки данных в системах отбора информации, применяемые для определения признаков слов или ключевых запросов в заданных документах.
С целью повышения эффективности работы алгоритмов поиска разработан метод автоматического разделения HTML-страниц на навигационную и содержательную части. Данный алгоритм рекомендуется к применению для узких задач информационного поиска, когда известно, что элементы оформления группы индексированных ресурсов мешают информационному поиску.
Библиографическая ссылка
Мельникова Д.А., Рыбанов А.А., Короткова Н.Н. ПРОЕКТИРОВАНИЕ И РАЗРАБОТКА АЛГОРИТМА ДЛЯ ПОВЫШЕНИЯ ЭФФЕКТИВНОСТИ СЕМАНТИЧЕСКОГО ПРЕОБРАЗОВАНИЯ ПОИСКОВЫХ ЗАПРОСОВ // Международный студенческий научный вестник. – 2018. – № 3-4. ;URL: https://eduherald.ru/ru/article/view?id=18384 (дата обращения: 26.04.2024).